Saturday, 12. January 2008
" Fußball ist keine Mathematik" verkündete Anfang November der Vorstandsvorsitzende einer bayerischen Ballsport AG. Welch eine triviale Erkenntnis, könnte der geneigte Fußballfan meinen. Doch leider macht es sich hier einer der bekanntesten Söhne Lippstadts etwas zu einfach.
Eigentlich kann mir das alles ziemlich egal sein. Es wäre mir auch keine Zeile wert, wenn besagter Fußballkenner nur so etwas wie "Fußball ist keine Franz-Ferdinand-Konzert" in den Notizblock der Journalisten diktiert hätte.
Doch hier schwadroniert jemand über Mathematik, der offensichtlich davon keinen Deut Ahnung hat. Denn Mathematik ist weit mehr als nur das Einmaleins und die Zins- und Zinseszinsrechnung.
Seit mehr als einem Jahrzehnt werden Bundesligaspiel für Bundesligaspiel jede Menge Daten erhoben, gespeichert und statistisch ausgewertet. Die Erkenntnisse, die sich daraus ableiten, werden dann z.B. in der Sportschau zum besten gegeben. Medien allegmein, aber auch die Fußballvereine versorgen sich mit Analysen auf Basis dieser Statistiken.
Einem Fußball-AG Vorstandsvorsitzenden sollte doch eigentlich bekannt sein, dass seine Angestellten solche Informationen bei ihrer Entscheidungsfindung mit einbeziehen.
Saturday, 14. April 2007
Dass Data Mining bei Versicherungen und Banken, im Handel oder in der Automobilindustrie gerne eingesetzt wird, gehört nun inzwischen zur IT-Allgemeinbildung. Aber dass sich die Fußball-Bundesliga für Mining-Analysen interessiert, das ist schon spektakulär.
Zu hören war das auf dem CeBIT BI-Forum anlässlich der Podiumsdiskussion mit dem (unsäglichen) Titel " Zweiter Frühling für Data Mining". Zu lesen ist diese Aussage auch in dem Referat des Moderators der Veranstaltung in der CW. Ich kann mich noch erinnern, dass Rolands Erwähnung der Fußball-Bundesliga weder beim Moderator noch bei den Mit-Diskutanten irgendeine Reaktion hervorgerufen hätte. Auch im CW-Artikel wurde das nicht vertieft.
Ist es schon so selbstverständlich, Data Mining in allen Lebensbereichen einzusetzen? Oder waren außer Roland auf dem Podium nur Fußball-Ignoranten vertreten?
Thursday, 22. March 2007
Die Zeit ist reif für den Data Mining-Sommer. Nein, kein Frühling (den hatten wir bereits), auch kein zweiter Frühling (wo war der Sommer dazwischen?), sondern Sommer. Die Gründe für diesen Optimismus wurden auf der CeBIT von der Expertenrunde unter dem Titel " Zweiter Frühling für Data-Mining?" mehr oder weniger deutlich herausgearbeitet.
- Data Mining ist als Disziplin gereift. Es liegt reichlich Erfahrung in unterschiedlichsten Anwendungsbereichen vor. Inzwischen verlassen auch mehr und mehr ausgebildete Data Mining Spezialisten die Universitäten.
- Data Mining Software ist erschwinglich. Nicht billig oder gar kostenlos, aber bei weitem nicht mehr so teuer wie noch vor einigen Jahren.
Man sollte jedoch vorsichtig sein: Nicht jede Data Mining-Aufgabe ist mit jeder x-beliebigen DM-Suite zufriedenstellend zu bewältigen. Je mehr unterschiedliche Algorithmen angeboten werden, desto bessere Ergebnisse können erzielt werden. Je mehr Data Mining als Prozess von der Daten-Akquisition bis zur Darstellung der Ergebnisse mit der jeweiligen Software implementiert werden kann, desto direkter sind die Ergebnisse nutzbar.
Sunday, 18. March 2007
Was sind wohl die Kosten, die ein Unternehmen für Data Mining Software kalkulieren muss. Die Antwort von Kennern der Data Mining-Szene: Data Mining gibt es bereits für lau, denn entweder kommt es im Bundle mit Datenbank-Software, oder es kommt als Open Source. Open Source scheint immer noch ein Synonym für kostenlos zu sein. Das alles ist ein großer Irrtum und dazu noch gefährlich.
An dieser Erkenntnis durfte ich am Freitag als Zuhörer einer Diskussion unter dem Titel "Zweiter Frühling für Data-Mining?" auf der CeBIT teilhaben. Sie wurden von den ausgewiesenen Data Mining Experten Wolfgang Martin und Peter Gentzsch zum Besten gegeben. Auch wenn beide viel Richtiges, aber auch nicht viel Neues zur Diskussion beitrugen, halte ich diese Einschätzung zu den Kosten von DM-Software für ziemlich daneben.
Denn das Martinsche Argument, dass DM-Software eingeschweißt in Datenbank-Pakete nichts oder nur wenig kostet ist nichts anderes als Schönrechnerei. Er meinte damit wohl die BI-Suites von IBM oder Microsoft. Offensichtlich wird Data Mining durch solche Bundles günstiger. Doch wie man es auch rechnet, die Kosten bewegen sich pro Prozessor komfortabel im fünfstelligen Bereich. Man sehe sich hierzu im Vergleich die reinen Kosten für die Datenbanken DB2 oder MS SQL Server an.
"Data Mining für lau?" vollständig lesen
Sunday, 18. February 2007
Bisher stand Data Mining nur für einen kleinen Kreis von Experten offen. Das wird sich ändern. Seit einiger Zeit arbeiten verschiedene Hersteller von Data Mining-Suites daran, diese Analyse-Software einem größeren Anwenderkreis zu öffnen. Am besten allen möglichen Anwendern - zumindest in jedem Unternehmen: " Data Mining for the masses".
Glücklicherweise gehörte ich auch zu dem erlauchten Kreis von Auserwählten, die Data Mining-Software auf ihrem Rechner installieren und nutzen konnten. Das waren und sind recht teure Einzelplatzlösungen, die -wenn überhaupt - nur durch sehr viel mühsame API-Programmierung einem größerem Kreis von Anwendern zugänglich gemacht werden konnten.
Die DB2 Data Warehouse Edition und hier insbesondere die Miningblox machen dem ein grausames Ende. Sie zerren Data Mining aus den Elfenbeintürmen der Analytiker und machen es für die staunenden Massen nutzbar. Und da die Miningblox auf einem Web Application Server laufen, also eine einfacher Browser als Frontend fungiert, sind dies nicht nur die Massen a la Microsoft - Systemvoraussetzung MS Windows -, sondern es kann wahrlich jedermann / jederfrau Mining-Analysen durchführen.
Sunday, 4. February 2007
Nach dem ich mich schon hinreichend über die neuen Algorithmen für das Data Mining in der Data Warehouse Edition gefreut habe, gibt es mit den "Miningblox" als weitere herausragenden Neuerung einen weiteren Anlass zu froher Erwartung.
"Miningblox: Miningblox tags extend Alphablox functionality with data mining. IBM provides a toolkit and a framework for BI developers so they can easily create custom mining solutions for their business users by using Web applications. The complexity of mining is hidden behind a common Web interface that empowers business users to use data mining without needing to install a database on their own systems."
Mit Miningblox wird also die Erstellung von Data Mining-Anwendungen erleichtert, die auf einem Application Server unternehmensweit zur Verfügung gestellt werden können. Das klingt nach wahrhaftigem "Data Mining for the masses", keine komplexen Software-Installationen auf allen Rechnern, die auf Mining-Analysen zugreifen sollen. Als Frontend genügt ein Browser.
Die Mining-Analysen laufen weiterhin in der Datenbank, hier unter Kontrolle eines Application Servers, der mittels Alphablox die Mining-Ergebnisse dem Anwender zur Verfügung stellt.
Aber bis dahin muss ich noch einige Steine aus dem Weg räumen:
"On the DWE WebSphere application server, you must manually deploy the Miningblox Framework. For more information, see the file readme.txt in the \mbx\install directory." (Miningblox: Administration and Programming Guide, S.5)
Das klingt nach zusätzlicher Arbeit.
Thursday, 25. January 2007
Der "mittelpunktbasierte" Clusteralgorithmus mit einer Kohonen-Karte lässt sich durch verschiedene Parameter beeinflussen. In den Mining-Einstellungen des Clusterer-Operators wird nach Auswahl von "Kohonen" als Algorithmus "Anzahl Durchgänge" angeboten. Die maximale Anzahl Cluster ist als Vorgabe für beide Segementierungsverfahren vorgesehen.
Bleiben noch die beiden Größen für die Bestimmung des "Zuordnungslayout": LayoutNumRows und LayoutNumColumns. Hierfür bietet der Clusterer-Operator keine eigenen Eingabefelder an. Es bleibt also nur die Spezifikation der Layoutwerte mittels "Optionale Parameter".
Und das ist nicht trivial, da sollte man schon mal die Online-Hilfe zu Rate ziehen. Die rät einem mehr oder weniger verklausoliert zu
DM_setAlgorithm('Kohonen','<LayoutNumRows>4</LayoutNumRows><LayoutNumColumns>5</LayoutNumColumns>').
Zumindest habe ich keine bessere Variante gefunden.
Saturday, 20. January 2007
Neural Networks are back!
"Kohonen Clustering: The Clusterer operator now provides the neural Kohonen Clustering algorithm." Dies ist ja eigentlich kein neuer Algorithmus: Das Clustern mit der Kohonen Karte kannte schon der gute, alte Intelligent Miner for Data. Ich habe dieses Verfahren oft als Alternative zur demographischen Segmentierung benutzt, die jeweils gebildeten Gruppen verglichen und mich dann doch meistens für das Ergebnis des demographischen Algorithmus entschieden.
Aber eben nur meistens. Es kann nicht falsch sein, zu einer Mining-Aufgabe verschiedene Verfahren zur Verfügung zu haben. So kann man sich einen besseren Überblick über das Problemfeld verschaffen.
Ich habe als Alternative zu einer Baumklassifikation, die die vor einigen Wochen erstellt hatte, testweise eine Naive Bayes-Klassifikation durchgeführt. In diesem Falle war ich mit dem neuen Ergebnis nicht sonderlich zufrieden, obwohl der Visualizer durchweg bessere Qualitätswerte ausweist. Denn die im Feldbedeutungsdiagramm angegebenen Einflüsse der Variablen waren und sind im Falle der Baumklassifikation realistischer.
Friday, 19. January 2007
Und nun zum Höhepunkt des DWE Refresh - zumindest aus meiner Sicht: die neuen " Data mining features". Ich meine damit nicht, dass die anderen Neuerungen marginal sind. Im Gegenteil, schon alleine die bisher beschriebenen Erweiterungen sind mehr als ich von einem "Refresh" erwarte. Von einem hunderstel Upgrade kann man höchstens etwas mehr als nur Fehlerkorrekturen erwarten.
Neue Mining-Algorithmen berechtigen eigentlich zu mehr als nur einem Hunderstel, z.B. zu 9.2 oder 9.5 oder gar zu 10.0. Dieses Refresh bring für mich mehr als eine komplette neue Windows-Version. Vista bringt die Menschheit nicht voran, wenn man mal von Intel oder AMD absieht. Lieber ein neuer Mining-Algorithmus als Tausend angeblicher Verbesserungen am GUI. MS ist doch inzwischen mehr damit beschäftigt, selbst aufgerissene Löcher zu stopfen als wirkliche Innovationen zu auszuliefern.
Aber das ist ein weites Feld. Ich komme lieber zurück zu den wichtigen und interessanten Dingen im IT-Leben, hier zu der Naive Bayes Klassifikation in der Data Warehouse Edition:
"Naive Bayes classification: The classification of information that is gathered from non-structured documents is a key element of structured and unstructured mining analysis. This algorithm provides this functionality with best acceptance throughout the industry. Naive Bayes classification is supported in the predictor operator."
Das ist eine Bereicherung für die Vorhersage kategorialer Variablen. Hier gab es bisher nur die Baum-Klassifikation, während zur Vorhersage kontinuierlicher Attribute sich gleich drei Verfahren anbieten. Es ist immer gut, eine Alternative zu haben. Trotz "naiver" Unabhängigkeitsannahmen liefert Naive Bayes häufig gute Ergebnisse.
Das ist aber noch nicht alles:
Sunday, 7. January 2007
Der DWE Data Miner war schon zu Zeiten des Intelligent Miners for Data ein Weltklasse Mining-Werkzeug. Allerdings gab es seit der Version 6.x des IM im Bezug auf Analyse-Funktionalität keine Neuigkeiten mehr. Statt dessen wurden die Mining-Methoden in DB2 als Intelligent Miner for Modelling und Scoring integriert.
In dieser Zeit - und die begann spätesten im Jahre 2000 - behaupteten andere Hersteller von Data-Mining-Software, dass IBM die Entwicklung eines eigenen Werkzeuges ausgegeben habe. Ich erinnere mich, dass in diesem Zusammenhang häufig SAS genannt wurde. Ich war zu der Zeit und bin auch noch der Ansicht, dass IBM dem hätte offensiver entgegentreten müssen. Denn die, wie sich herausstellen wird, haltlosen Behauptungen mancher Wettbewerber wie SAS, SPSS, Oracle und neuerdings Microsoft grenzten schon an wettbewerbsschädigendem Verhalten.
Doch die DWE 9.1 und vor allem das Refresh sprechen eine deutliche Sprache. Die Integration von Mining-Technologie in das Data Warehouse-Umfeld ist aus meiner Sicht mehr als gelungen. Ich vermisse den Intelligent Miner for Data fast überhaupt nicht mehr. Die Abbildung des gesamten Data Mining-Prozesses, angefangen bei der Datenakquisition bis hin zur Darstellung der Ergebnisse, ist im Design Studio wesentlich einfacher und transparenter zu gestalten, als es vor der Version 9.1 der Fall war.
Mit DWE Version 9.1 habe selbst ich eingesehen: Die Mining Work Bench a la Intelligent Miner for Data ist tot, es lebe die Integration von mathematischer Intelligenz ins Data Warehousing.
Der Refresh bringt nun drei neue Mining-Algorithmen. Das gab es schon seit langem nicht mehr, dass die Kernfunktionalität des Miners erweitert wurde. Dazu kommen noch mit den Miningblox eine Neuerung, die die Darstellung von Mining-Ergebnissen ins Reporting-Umfeld integriert.
Das ist doch nicht normal für einen Refresh.
"Was gibt's Neues in DWE 9.1.1 (Data Mining Prolog)" vollständig lesen
Sunday, 12. November 2006
Da war ich doch etwas voreilig mit meinem Wunsch nach einer Möglichkeit, Mining-Modelle im Design Studio zu verwalten.
 Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.
Und nicht nur das: Ein rechter Mausklick auf ein Modell öffnet ein Menü mit den Einträgen "Öffnen", "Löschen", "Umbenennen" und "Exportieren".
Saturday, 28. October 2006
Bevor man Data Mining in DB2 betreiben kann, muss vorher die jeweilige Datenbank dafür vorbereitet werden. Dies geschieht mit
idmenabledb ... fenced dbcfg
im DB2 Befehlsfenster (wobei an Stelle von ... natürlich der Datenbankname stehen sollte).
Damit wird ein Schema erstellt, unter dem dann einige Tabellen und eine Vielzahl von Anwendungsobjekten (datentypen, Funktionen, Prozeduren und Methoden) angelegt werden.
Im Design Studio gibt es hierzu (noch) keinen Eintrag im Kontextmenu der Datenbank, so wie es das die Anlage der OLAP-Objekte vorgesehen ist. (23.11.2006: Tatsächlich findet man solch einen Eintrag im Datenbankexplorer)
Monday, 23. October 2006
Diese Ankündigung habe ich noch nicht bei ibm.com gefunden. Daher gibt es hier auch keinen Link, und daher konnte ich keine Details nachsehen. Einige Fragen bleiben also offen, spätestens bis ich die Version 9.1.1 installiert habe.
Das wird dann auch nicht mehr solange auf sich warten lassen: am 1.12. steht der Refresh zum Download bereit, also noch im 4.Quartal, so wie prognostiziert.
Die wesentliche Neuerung dieser Hundertstel-Version ist die Einbindung der aktuellen DB2-Version 9.1. Dies hätte möglicherweise auch mit der DWE 9.1 funktioniert, aber mit der 9.1.1 ist es nun offiziell. Und man weiß ja nie, was so passieren kann.
Damit stehen nun der DWE alle neuen Features der DB2 9 wie
- Self-Tuning Memory Management
- Table (Range) Partitioning und
- Table (Row) Compression
zur Verfügung. So zu lesen in der Ankündigung. Mal sehen, wie sich dies im SQW niederschlägt.
Wednesday, 7. June 2006
"Hierzu kommt vor allem bei Microsoft das Argument, dass die Dienste für Data Warehousing und Datenintegration kostenlos mit der Datenbank erhältlich sind."
Dies war in einem Bericht über die "Data Management Expo" von Barc und der Computerwoche (" Nichts geht mehr ohne Daten-Management", CW 15.05.2006) in eben dieser zu lesen.
Lese ich Microsoft und Barc? Da war doch noch was? Gerade heute tollen sich Microsoft und Barc gemeinsam durch Deutschland unter dem Motto "Roadshow - Business Intelligence mit Microsoft". Barc und die CW beglückten die deutschen Daten-Manager gemeinsam mit einem Kongress. Bei so viel Gemeinsamkeit ist es keine Überraschung, dass solche Statements in meiner wöchentlichen Pflichtlektüre auftauchen.
Die CW konsultiert doch gerne " Kenner" irgendeiner Szene. Vielleicht hätte der eine oder andere "Kenner der Datawarehouse-Szene" das eine oder andere zurecht gerückt.
"Wes Brot ich ess ..." vollständig lesen
Friday, 3. March 2006
Das Cairos-System gab mir bishjer Anlass zu drei Vorträgen:
Den Erste ging zum Thema "Fußball, Mathematik und APL" unter dem damals schon zum zweiten Male verwendeten Titel "Der Ball ist rund, ein Spiel dauert 10 GB". Ich habe nicht mal ein Copyright auf diese Formulierung. Wenn sie schützenswert wäre, hätte Christiane den Anspruch auf das geistige Eigentum. Das erste mal hat unter dieser Headline Dirk einen von mir erstellten Foliensatz zum Thema Data Minig im Sport auf einer IBM-Veranstaltung in Dortmund vorgetragen.
Doch zurück zu APL und Fußball:
Ende 2003 bekam ich von Marcus simulierte Positionsdaten über die 10 Sekunden vor und während des ominösen Wembley-Tors. Das waren ca. 20.000 3D-Koordinaten. Mit meinen APL-Baukasten und ein wenig Mathematik konnte ich daraus die Spielzüge als einen Satz von Polynomen reproduzieren. Das war einfach, zu einfach, da es keine real-life Daten waren. Mit echten Daten aus dem Cairos-System hätte ich schon mehr Probleme gehabt. Damals war das System aber noch nicht so weit.
So war ich mit Hilfe von Taylor-Reihen schnell erfolgreich. Mit APL und Grundkenntnissen in Analysis machte das auch noch Spaß. Ich habe natürlich versucht, das alles per Präsentation auf einem GSE-APL Treffen rüberzubringen, also quasi zu Hause und im Trikot von Stefan Reuter.
Meine Erkenntnisse und Ergebnisse von damals konnte ich seitdem nicht mehr anwenden. Was bleibt ist ein Satz analytischer APL-Funktionen und ...
der Beweis, dass der Ball nicht hinter der Linie war!
|
 Bleiben noch die beiden Größen für die Bestimmung des "Zuordnungslayout": LayoutNumRows und LayoutNumColumns. Hierfür bietet der Clusterer-Operator keine eigenen Eingabefelder an. Es bleibt also nur die Spezifikation der Layoutwerte mittels "Optionale Parameter".
Bleiben noch die beiden Größen für die Bestimmung des "Zuordnungslayout": LayoutNumRows und LayoutNumColumns. Hierfür bietet der Clusterer-Operator keine eigenen Eingabefelder an. Es bleibt also nur die Spezifikation der Layoutwerte mittels "Optionale Parameter".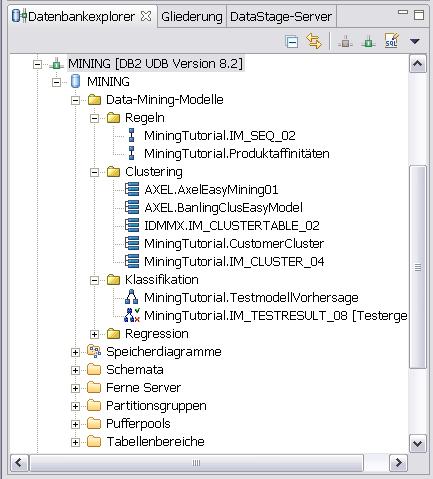 Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.
Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.
 ap127
ap127