Thursday, 24. August 2006
Wie bekomme ich bloß meine Daten aus MS Access in mein Data Warehouse?
Fürs erste habe ich sie mühsam in eine CSV-Datei exportiert, um sie mit dem Dateiimportoperator in die dafür vorgesehen DB2-Datenbank zu importieren.
Um das ganze aber weniger händisch betreiben zu können, hatte ich vor, nach einer JDBC-ODBC-Bridge zu googlen. Aber auch das wäre viel zu kompliziert gewesen. Martin erinnerte mich daran, dass DB2-Tabellenfunktionen auch OLEDB unterstützen.
Die Umsetzung dauerte dann nur einige Minuten: In der DB2 Entwicklungszentrale mit dem Assistenten eine OLEDB-Tabellenfunktion erstellen und diese dann im DWE Design Studio mittels des Tebellenfunktionsoperators zum Ausgangspunkt eines Datenfluss machen.
Es geht sogar noch etwas einfacher.
Tuesday, 22. August 2006
Namen sind angeblich nur Schall und Rauch. Das sollte dann auch für Namen in Datenbanken gelten. Ob eine Tabelle nun "Umsatz" heißt oder "xxx" ist der Datenbank egal.
Ich mache aber immer wieder die Erfahrung, dass es zwar egal ist, welchen Namen das Datenbankkind bekommt, aber der sollte wenigstens groß geschrieben werden. Das gilt für Namen von Datenbanken selbst, sowie für Namen von Objekten in einer Datenbank.
Immer, wenn ich diesem Prinzip nicht gefolgt bin, hatte ich später irgendwo größeren Schreibaufwand. Manche Anwendungen gehen schon mal davon aus, dass Schema- oder Tabellennamen groß geschrieben sind.
Zumindest ist diese Regel besser als die blödsinnigen eckigen Klammern, die Access verwendet.
Monday, 21. August 2006
 Was steht im Titel? Es ist untersagt hier weiter zu lesen.
Also raus jetzt.
...
"Dies nicht lesen" vollständig lesen
Sunday, 20. August 2006
Noch ein Wort zum Dateiimport-Operator des SQL-Warehousing-Tools der DB2 Datawarehouse Edition:
Das Semikolon scheint als Trenner zwischen Feldern nicht vorgesehen zu sein.
Einige Formate lassen sich definieren: Datum, Zeit und Zeitstempel. Unter den wählbaren Datumsformaten fehlt mir DD.MM.YYYY. Irgendwie konsequent ist daher, dass das kontinental-europäische Dezimalkomma nicht unterstützt wird.
Zahlenformate sind nicht wählbar. Beim Exportieren aus (z.B.) MS Access muss also das voreingestellte Dezimalzeichen von "," auf "." geändert werden. Entsprechendes wird für Datumstrennzeichen gelten.
Ist der NLS noch unvollständig oder habe ich da was übersehen?
Lesen bildet, manchmal selbst das Lesen von solch Meisterwerken wie Online-Hilfen. Ich bin stets freudig überrascht, wenn dies umgehend zu praktisch verwertbaren Erkenntnissen führt wie z.B. die prompte Beantwortung meiner "Dateiimport"-Frage .
Ich hätte diese Frage auch anders klären können: Durch einen Blick ins Log.
Dazu sollte man unter Datenfluss/Ausführen auf der Seite "Diagnose" eine Tracestufe auswählen. Aber Vorsicht: Die Tracestufe "Beides" kann ein sehr großes Logfile nach sich ziehen.
Die Tracemeldungen werden nach Beendigung der Ausführung im "Auführungsergebnis" präsentiert. Ungeduldige können sie ruhig mit "OK" wegklicken. Sie sind bereits unter ...\workspaces\[Projektname]\run-profiles\logs gespeichert.
Handbücher beschreiben die Theorie, Logfiles dagegen die Praxis.
Wednesday, 16. August 2006
Ich mag Handbücher, die meine Fragen bereits antizipiert haben.
Eigentlich vermeide ich die Konsultation von solchen Dokumenten, aber manchmal geht es nicht ohne. 2,5 GB bringen entsprechend viel Dokus und Tutorials mit sich - soweit ich gesehen habe mehrere 100 MB. Die werde ich nicht alle lesen.
Hier meine Frage, die unbürokratisch von der Online-Hilfe beantwortet wurde:
Mein Datenfluss hat einen Dateiimportoperator als Quelle und verzweigt sich danach sofort in drei Operatoren-Stränge. Da der Dateiimportoperator eine große CSV-Datei einliest und konvertiert, könnte es ja sein, dass dies möglicherweise dreimal durchgeführt wird - für jeden Zweig am Ausgabe-Port des Dateiimports einmal.
Glücklicherweise gibt es den Datenstationsoperator. Dieser speichert jede Tabelle zwischen - als Datei, als View, als temporäre oder als permanente Datenbank-Tabelle. Dieser Operator wäre also in der Lage, ein mögliches mehrfaches Einlesen zu verhindern.
Aber ist das explizite Einbauen eines Datenstationsoperators wirklich notwendig. Oder ist das SQL Warehousing-Tool (SQW) der DWE schlau genug und baut so einen Operator selbstständig ein?
Tuesday, 15. August 2006
Das ist wahre Begeisterung: Nachdem ich den Plan für mein eigenes DWE-Tutorial niedergeschrieben hatte, konnte ich bis 4 Uhr morgens nicht mehr die Finger davon lassen. Die erste Etappe habe ich auch tatsächlich erfolgreich beendet. Der Rest ist dann OLAP.
Zugegeben: Es ist nicht immer alles glatt verlaufen. Aber das sind die typischen Probleme in der Kennenlernphase einer neuen Software. Immerhin habe ich keine Dokumentation zu Rate ziehen müssen und auch nicht wollen. Fast alles erklärt die Software selbst. Eigentlich überraschend.
Ok, ich habe ein, zwei mal im offiziellen DWE Tutorial nachgeschaut.
Hier in Überschriften das Protokoll dieses famosen Projektstarts: - Anlegen einer leere Datenbank mit DB2-Bordmitteln
- Anlegen eines "Data-Warehouse-Projekts" im Design Studio (ich mag das DWE Design Studio, denn das Design Studio basiert auf Eclipse)
- Importieren der Metadaten der unter 1. angelegten DatenbankAnlegen eines "Datenfluss" zum Importieren der Daten aus MS Access
- Definieren eines "Dateiimport"-ObjektesOperators
- Erstellen des Modells für die Zieltabelle
- Definieren eines "Massenladeziel"-ObjektesOperators zum Befüllen der Zieltabelle mit den importierten Daten
- Prüfen des Datenflusses
- Erstellen der neuen Tabelle (siehe 6.) in der Datenbank
- Ausführen des Datenflusses
Nachdem 10. erfolgreich war, wurde ich mutig und habe noch zwei weitere, ein wenig längere Datenflüsse gebaut.
Hier noch einige Details zu den Überschriften:
Monday, 14. August 2006
... oder zu neuschwäbisch: Business Intelligence. Das soll mit der DB2 Datawarehouse Edition erreicht werden können. Nun gut, lasst es uns testen!
Dazu nehme ich eine alte MS-Access-Anwendung her, um sie beispielhaft zu portieren und zu verbessern. Dies ist mein Tutorial zum Einstieg in die Data Warehouse Edition.
Nachdem ich hier die Installation der DWE beschrieben und kommentiert habe, werde ich dies teilweise für dieses kleine DWE-Projekt tun. Dies soll der Dokumentation und der Wiederverwendbarkeit dienen.
Und hier die Aufgabe: Einlesen der Daten aus einer Access-Tabelle, Erstellung eines OLAP-Modells für diese Daten, Erstellung des Würfels und Implementierung der wichtigsten Reports und Analysen mit Alphablox.
Anders als meine Access-Anwendung, kann ich dann alle Prozesse und Analysen auf einem Server ausführen und auf die Ergebnisse mit einem Browser zugreifen. Dies fördert die Klugheit eines Unternehmens.
... würde Franz Ferdinand sagen.
Es war einfacher, als ich anfänglich dachte. Mal so eben 2,5 GB Software installieren und konfigurieren, und es läuft. Tatsächlich.
Ich schreibe hier über die DB2 Data Warehouse Edition (DWE). Ein umfangreiches Software-Bundle mit Business Intelligence (BI) Anwendungen. Die DWE Enterprise Edition besteht aus folgenden Komponenten: - die Datenbank DB2 Enterprise Edition
- das Data Warehouse Design Studio
- das SQL Warehousing Tool
- OLAP Acceleration
- Data Mining
- Alphablox Analytics
- und viele andere nette Tools inkl. dem Websphere Application Server
Viel Software für viel Geld. Die gibt es auf CDs oder per Download aus dem Netz.
Ich habe mich für zweiteres entschieden. Also habe ich über Nacht die IBM um 4,4 GB gezippte Dateien erleichtert, das komplette Rundum-fühl-dich-wohl-Paket.
Der Plan war nun alles, d.h. Client- und Server-Komponenten auf meinem Thinkpad zu installieren. Das ist untypisch, aber zum Entwickeln, Prototypen und Testen sehr praktisch.
Sunday, 13. August 2006
... ist ein weitreichendes und komplexes Unterfangen. Deshalb habe ich bisher tunlichst nur handverlesene Teilbereiche betrachtet.
Man suche z.B. einige Funktionen aus, die eine Datenbank bieten sollte, und vergleiche die Qualität der Unterstützung für ausgesuchte Datenbanken. So geschehen in " Die zweitbeste Datenbank der Welt". Man sollte auch die verglichenen Funktionen nennen, was ich dort offensichtlich nicht getan habe.
Das hole ich hier nach, nicht vollständig und auch nicht in der Reihenfolge des Vergleichs: Partitionierung, XML-Unterstützung, "Self Tuning" und Komprimierung.
Es müssen ja nicht nur Funktionen oder Features sein, es können auch Lizenzbedingungen sein. Das ist oft nicht weniger interessant, wie " Freie Datenbanken von unfreien Anbietern" zeigt.
Aber alles beleuchtet nur einen kleinen Ausschnitt. Ich denke, man kann ... wo ich das gerade schreibe, kommt auf meinem Rechner der RSS zu einem CW-Artikel zu einem DB-Benchmark-Tools herein. So ein Zufall.
Bernd hat den zweiten Vergleich getrackbackt. Dort wünschte sich ein Kommentator einen Vergleich der "Performance und Leistungsfähigkeit". Das ist nun ein schwierigeres Unterfangen, dem ich auch hier nicht nachkommen werde.
Doch einige Bemerkungen zu diesem Thema möchte ich hier loswerden:
Saturday, 12. August 2006
Warum migrierte Quelle von Oracle auf den SQL-Server? Schade für Oracle, eigentlich egal für den Rest der Welt.
Denn nicht alle Datenbanken wurden migriert, sondern nur die einer Anwendung für Außendienstmitarbeiter. Ich habe keine Ahnung, warum dies der CW eine ganze gedruckte Seite wert war (immerhin erstreckt sich die digitale Ausgabe über 4 Seiten).
Kurz zusammengefasst: Die bisherige Außendienst-Software erschien zukünftigen Ansprüchen nicht mehr erfüllen zu können. Man fand bei Neckermann (gehört wie Quelle auch zum KarstadtQuelle-Konzern) die Basis für ein neues System. Das Neckermann-System nutze den SQL-Server als Datenbank. Das scheint der unspektakuläre Hintergrund der Geschichte zu sein.
Aber mein Lieblingsredakteur ue wäre nicht ue, wenn er sich nicht aufgrund seiner hervorragenden Kenntnis der Datenbankszene erlauben würde, mehr daraus macht. Was er denn auch tat.
Wednesday, 9. August 2006
MySQL macht's möglich: Nun gibt es auch von allen drei großen Datenbank-Anbietern freie Versionen ihres DBMS. Frei im Sinne von Lizenzgebühren. Frei aber nicht von verschiedensten Beschränkungen.
Welches freie Angebot welchen Unfreiheiten unterliegt, soll folgende Übersicht zeigen.
| DB2 Express-C | MySQL Pro | Oracle XE | SQL Server Express | | Betriebssystem | Linux, Windows | Linux, Windows, einige UNIX | Linux, Windows | natürlich nur Windows | | max. RAM-Größe | 4 GB | keine Begrenzung | 1 GB | 1 GB | | 32/64 Bit | 32/64 | 32 | 32 | 32 | | max. Anzahl Prozessoren | 2 CPU dual core | keine Begrenzung | 1 | 1 | | max. Größe einerDatenbank | keine Begrenzung | keine Begrenzung | 4 GB | 4 GB | | FreeProduction/ Redistribution | ja/ja | nein/nein (nur mit kommerzieller Lizenz) | ja/ja | ja/ja | | Support | Forum und/oder gegen Gebühr | Forum und/oder gegen Gebühr | nur Forum | nur mit Upgrade |
Offensichtlich sind die Spalten alphabetisch nach den Einträgen im Spalterkopf sortiert, oder ...
Na, welches FOSS DBMS sieht da am besten aus? Das ist doch einfach zu sehen:
Monday, 7. August 2006
Ted Codd mag zwar Anfang der 90er den Begriff OLAP (Online Analytical Processing) kreiert haben, aber er hat damit nicht die mehrdimensionale Speicherung und Analyse von Daten erfunden.
Dies geschah lange bevor Codds meinte, die Computerwelt mit seinen komischen 12 OLAP-Regeln beglücken zu müssen.
1998 schrieb Mark Hammond in der PC Week unter dem Titel "It's not Greek to me": OLAP has its roots in a multidimensional language called APL, developed in 1962, that used Greek symbols and ran on IBM mainframes.
Für einen APLer war und ist das Denken in und das Arbeiten mit multidimensionalen Strukturen selbstverständlich. Von daher haben wir den Hype um OLAP nie so recht verstanden. Wir hatten ja schon lange alles, was OLAP angeblich ausmacht, und noch vieles mehr.
Anbieter von OLAP-Software können noch viel von APL lernen. Nur die Speicherung von dünn besetzten Würfeln ist bei den meisten OLAP-Systemen effizienter gelöst.
Saturday, 5. August 2006
Nein, ich will nicht immer nur über böse Bubenstreiche der CW schreiben. Denn die meisten Artikel sind ok, informativ und sachlich. Es gibt auch auch die von der Sorte "fassungsloses Kopfschütteln". Bei manchen Fragen ist ein Redakteur mit technischen Details einfach überfordert und sucht und findet leider die falschen Ratgeber.
Ich habe also einige Ausgaben der CW mit dem Vorsatz gelesen, mal einen erwähnenswert guten Artikel zu finden. Und tatsächlich, ich wurde fündig:
" Microsoft umgarnt die Open-Source-Szene"
Anders als ein Kollege erinnert der Autor sich sehr wohl daran, wer unter dem Schafpelz steckt. Tatsächlich glaube ich nicht, dass die CW Microsoft-freundlich ist.
Es gibt aber leider diese bösen Unfälle.
Friday, 4. August 2006
Ich habe mich ja schon länger nicht mehr über die Computerwoche echauffiert. Obwohl ... in der heutigen Ausgabe gäbe es was, da hat mich so ein Gefühl von Bildzeitung überkommen. Dabei bleibt es dann aber auch.
Für so eine "saure Gurken"-Zeit habe ich noch einen Aufreger in Reserve.
Mai 2005 : Google beklagt sich über Microsoft
Es geht um den Schrott-IE, der in Version 7 als Suchmaschine MSN voreingestellt hat, was Google bitterlich beklagt. Aber man kennt ja Mickeysoft, sie versuchen es immer wieder.
Das kann mir ja eigentlich alles am ... vorbeigehen, denn ich verwende den IE nicht und habe auch in meinem Firefox Google voreingestellt. In meiner Welt ist zumindest das gut.
Außerdem: was schert mich der Krach zweier Monopolisten, sollen sie sich doch gegenseitig zerfleischen.
Interessant ist aber, was die CW aus der ganzen Sache macht. Man kann rein sachlich darüber berichten, mehr als eine Nachricht ist die Sache ja nicht wert.
Man kann aber auch Partei ergreifen, und das tut die CW: für Microsoft - als ob die es nötig hätten.
|
 Zugegeben: Es ist nicht immer alles glatt verlaufen. Aber das sind die typischen Probleme in der Kennenlernphase einer neuen Software. Immerhin habe ich keine Dokumentation zu Rate ziehen müssen und auch nicht wollen. Fast alles erklärt die Software selbst. Eigentlich überraschend.
Zugegeben: Es ist nicht immer alles glatt verlaufen. Aber das sind die typischen Probleme in der Kennenlernphase einer neuen Software. Immerhin habe ich keine Dokumentation zu Rate ziehen müssen und auch nicht wollen. Fast alles erklärt die Software selbst. Eigentlich überraschend.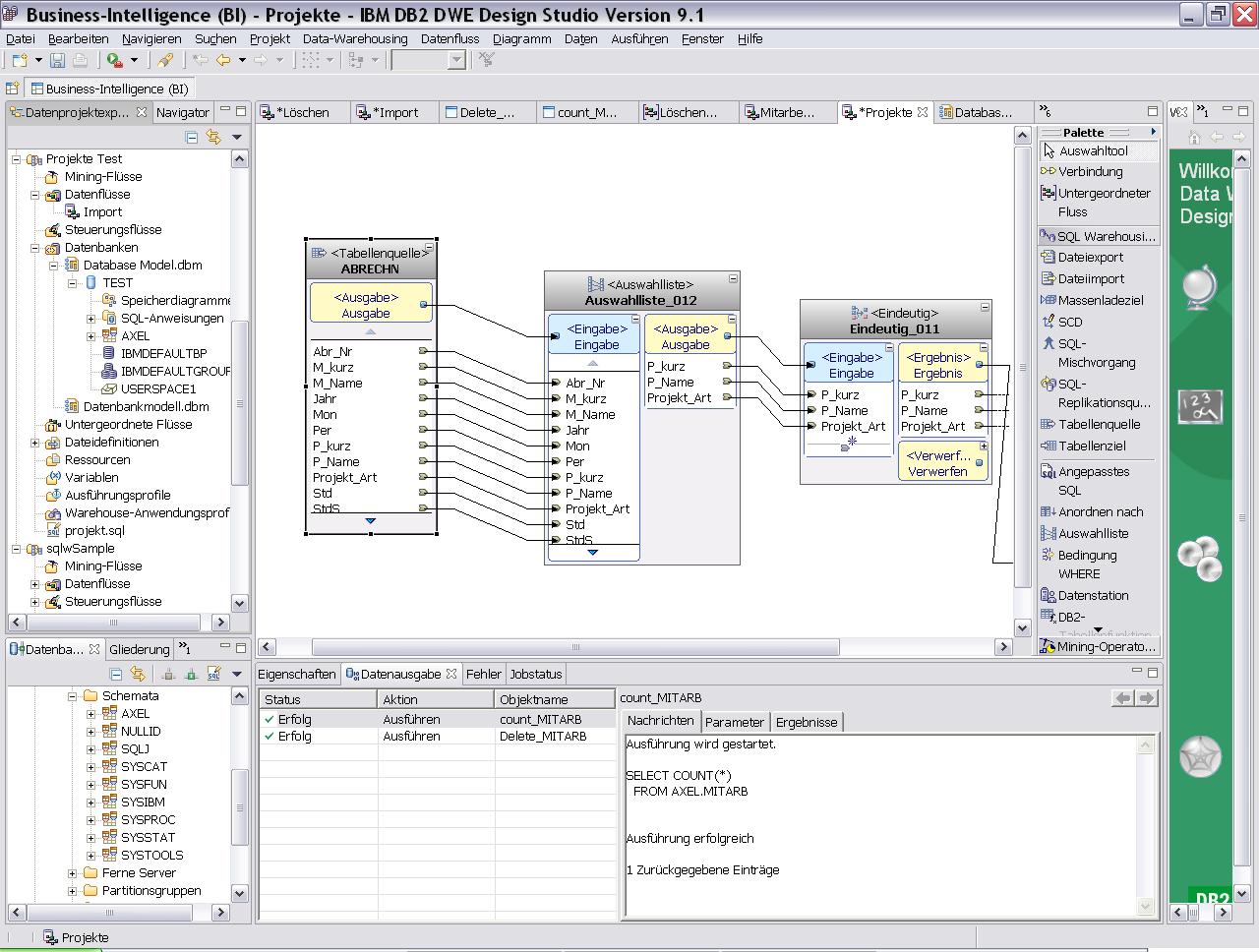

 ap127
ap127