Saturday, 30. December 2006
Das gab es auch schon für die DWE Version 9.1: die " Post-Installation tasks". Dazu gehört die Konfiguration diverser DWE-Komponenten: Intelligent Miner, Alphablox, Application Server und das Information Center (s.a. DWE Installation Guide, Chapter 7).
Ich habe mir bisher diese Tätigkeiten geschenkt, da ich sie bereits bei der Installation der Version 9.1 erledigt habe, und sich durch die neuen 9.1.1-Komponenten an der Konfiguration von Alphablox und dem WAS nichts verändert haben sollte. Die "Post-Installation Task" für den Miner besteht unter Windows sowieso nur im " Enabling" von Datenbanken für das Mining.
Zusätzlich zu diesen Aufgaben kommt noch für die 9.1.1 die Installation der Miningblox und das Upgrading der DWE Control Datenbank.
Als weitere "Post-Installation task" kann man auch die folgende Empfehlung aus dem Installation Guide (S.39) betrachten:
"To verify that the installation was successful, check the log files listed in Appendix B, “Log file locations,” on page 53. In the main installation log file dweinstall.log, check the lines that contain keywords such as err, Exception, wrn for errors and warnings." Dem bin ich ausnahmsweise mal nachgekommen, da mein Upgrade nicht ganz perfekt war. Im logs-Verzeichnis meiner DWE-Installation war tatsächlich nur dweinstall.log mit einem aktualisierten Zeitstempel versehen. Die anderen Installationslogs waren - wie zu erwarten war - unverändert.
Thursday, 28. December 2006
Die eigentliche Rechtfertigung für die seit Anfang dieses Monats verfügbare Data Warehouse Edition 9.1.1 ist die Unterstützung einiger Neuerungen der DB2 9. Aber nicht nur deshalb habe ich meine Datenbankversion unabhängig und als Erstes aktualisiert.
Da sich außerdem bei Alphablox und dem Websphere Application Server nichts verändert hat, müssen nur noch zum Upgrade auf die DWE Version 9.1.1 die neuen Komponenten des SQW, des Intelligent Miner und der DWE Administration installieren werden. Das erledigt die aktuelle Variante des Integrated Installers.
Hier brauchen also unter "Implementierungsoptionen" die "Anwendungsserverkomponenten" nicht ausgewählt werden ( 01.01.2006: tatsächlich muss eine Anwendungsserverkomponente - die DWE Verwaltungskonsole - aktualisiert werden). Die sind ja bereits installiert. Das gleiche gilt in diesem Fall für DB2, es kann daher eine "vorhandene DB2-Kopie" verwendet werden.
In der Auswahl der DWE-Komponenten können dementsprechend serverseitig DB2 und der Query Patroller abgewählt werden. Das Gleiche gilt für den Client. Unter Dokumentation kann man auf die "Alphablox Informationszentrale" verzichten. Eigentlich kann man das auch für die Cube Views-Komponenten abwählen, sicherheitshalber habe ich sie aber mitgenommen.
Die folgende Installation dauert eine Weile, immerhin werden 823 MB Daten bewegt.
Tuesday, 26. December 2006
Und hier ist die Theorie zur Praxis:
DB2 Explain schätzt für das teuerste Test-Select auf die umdefinierte Tabelle in unkomprimierter bzw. komprimierter Form folgende den Aufwände:
| unkomprimiert | zeilenkomprimiert | | | Gesamtaufwand | 111.757,9453125000 Timeron | 49.764,9921875000 Timeron | 45% | | CPU-Aufwand | 6.189.640.704 Anweisungen | 7.847.347.712 Anweisungen | 127% | | Ein-/Ausgabeaufwand | 107.542 E/As | 44.191 E/As | 41% | | Aufwand der ersten Zeile | 1.755,8646240234 Timeron | 786,0233154297 Timeron | 44% |
Danach wäre der Aufwand für die Ausführung des analysierten Selects für die verdichtete erheblich niedriger. Auf den ersten Blick passt das nicht so richtig zur Praxis, die bestenfalls einen Gleichstand ergab.
Bei näherem Hinsehen wird klar, dass der Gesamtaufwand nahezu komplett durch den geschätzten I/O bestimmt wird. Eine Verringerung des I/O bewirkt fast 10-mal stärker eine Reduzierung des Gesamtaufwandes als eine entsprechende Verminderung der CPU-Anweisungen. Das begründet große Performance-Vorteile für Zugriffe auf stark komprimierbare Tabellen.
Für unkomprimierte Tabellen, die komplett in den Buffer passen, entfällt der Aufwand für I/O. Dagegen entsteht für den Zugriff auf das (ebenfalls komplett im RAM abgelegte) komprimierte Analogon ein zusätzlicher CPU-Aufwand durch Dekomprimierung, der nun ungebremst zu einer entsprechenden Erhöhung des Gesamtaufwandes führt.
Die Theorie zeigt also, dass sich in besagter Praxis die Select-Anweisungen hauptsächlich aus dem Buffer bedient haben müssen.
Übrigens: der Aufwand für E/A entspricht hier der Größe der jeweiligen Tabelle in Anzahl 4K-Pages (npages).
Monday, 25. December 2006
Man kann eben nicht alles haben.
Die gleichen Performance-Vergleiche, die ich für die Original-Tabelle und ihr komprimiertes Abbild durchgeführt habe, habe ich auf die beiden umdefinierten Tabellen angewandt. Ich konnte keinen signifikanten Unterschied feststellen, egal in welcher Reihenfolge ich sie abgespielt habe.
Wenn überhaupt eine leichte Differenz zu erahnen ist, dann zuungunsten der komprimierten Variante. Mag sein, dass in beiden Fällen die Selects sich im Wesentlichen aus dem Buffer bedienen, also kaum teuren I/O produzieren. Für die Ergebniszeilen der komprimierten Tabelle kommen zusätzlich noch die CPU-Zyklen für die Dekomprimierung hinzu.
Das mag den - wenn überhaupt - kleinen, nicht signifikanten Unterschied erklären.
Sunday, 24. December 2006
Nachdem meine erste Zeilenkomprimierung einer Tabelle eine hohe Verdichtungsrate aufgrund suboptimalen Designs erbrachte, fragt sich nun, ob der Tabelle mit verbesserter Definition ein ähnlich hohes Sparpotenzial innewohnt.
Natürlich konnte ich nicht wieder 78% erwarten, aber die Vorhersage (inspect rowcompestimate) war dennoch erfreulich:
Prozentsatz der durch die Komprimierung gesparten Seiten: 58
Prozentsatz der durch die Komprimierung gesparten Byte: 58
Prozentsatz der Zeilen, die wegen geringer Zeilengröße nicht für die Komprimierung ausgewählt werden können: 0
Größe des Komprimierungswörterverzeichnisses: 45824 Byte.
Größe des Erweiterungswörterverzeichnisses: 32768 Byte.
Also weniger als die Hälfte des Platzes der unkomprimierten Tabelle, nicht schlecht!
Und tatsächlich: Statt 107541 4K-Seiten belegt die Tabelle nach "alter table ... compress yes" und dem Reorg nur noch 44171 Seiten. Dies ist eine Verdichtung auf 41%.
Die Prognose durch rowcompestimate war wieder sehr treffend. Man kann sich wohl darauf verlassen.
Wednesday, 20. December 2006
Meine Tabelle zum Experimentieren mit der Venom-Komprimierung hat einige Design-Schwächen, die zu der überraschend hohen Kompressionsrate geführt haben.
Die Unachtsamkeit beim der Definition des Tabellen-Layouts lag darin, dass die meisten Spalten als char mit konstanter Länge vorgegeben wurden. Darunter sind Felder für die Aufnahme von Namens- und Adressdaten, deren Längen so gewählt wurde, dass der längste Nachname oder der längste Straßenname komplett aufgenommen werden konnte.
Damit wird viel Speicherplatz mit rechtsbündig auffüllenden Leerstellen verschwendet. Die Mehrzahl dieser Spalten sind mit weniger als 20% Sinn tragender Daten gefüllt. Ein Defizit, das durch die neue Zeilenkomprimerung ohne großen Aufwand gut kaschiert werden konnte.
Aber es geht doch auch anders, auf klassischem Weg: sorgfältigeres Design. So konsumiert z.B. eine als varchar(50) statt char(50) definierte Spalte im vorliegenden Fall 80% weniger Speicherplatz.
Zusammen mit entsprechenden Änderungen für Spalten mit stark unterschiedlich langen Zeichenketten ergibt das eine Reduktion der durchschnittlichen Zeilenlänge um 56% (select avgrowsize from sysibm.systables where name= tabellename). Für die absolute Größe der beiden Tabellen bedeutet das 244026 4K-Pages der Originaltabelle gegenüber 107541 Pages der Tabelle mit den geänderten Datentypen.
Manchmal macht eben eine Komprimierung per Hand noch vor Einsatz aufwändiger Algorithmen Sinn.
Tuesday, 19. December 2006
Überraschend und auch nicht überraschend.
Gemeint ist hier der Zugriff auf zeilenkomprimierte DB2 9 Tabellen. Denn das Selektieren von Daten bedeutet eben nicht nur Lesen von Bits und Bytes von Platte oder aus dem Datenbank-Buffer, sondern auch noch das rechenintensive Dekomprimieren der extrahierten Daten. Letzteres belastet den Prozessor mit Mehrarbeit.
Andererseits sinkt durch den geringere Größe der komprimierten Daten der Aufwand für I/O. Darüberhinaus kann aufwändiger I/O durch den wesentlich schnelleren Griff in den Buffer ersetzt werden, denn durch die Komprimierung kann dieser größere Teile der Tabelle im RAM vorhalten.
Es ist also ein Geben und Nehmen. Allgemein wird keine konkrete Vorhersage zu der Auswirkung der Zeilenkomprimierung einer Tabelle auf die Performance eines Zugriffs möglich sein. Bisherige Erfahrungen gehen davon aus, dass sich die Bearbeitungszeit für SQL-Statements nicht verschlechtert, und wenn Unterschiede festzustellen sind, dann zugunsten der komprimierten Variante.
Ich habe also erwartet, dass sich für meinen Test die Performance möglicherweise geringfügig verbessert. Dieser besteht ausschließlich aus Select-Statements, die einen unter Verwendung von Indexspalten, die anderen erfordern einen Scan der Tabelle.
Monday, 18. December 2006
... so geht's. Genau genommen ist das Thema: Die Zeilen einer Tabelle unter Verwendung eines Verzeichnisses komprimieren. Das von DB2 dazu verwendete Kompressionsverfahren namens "Venom" arbeitet dabei mit dem Lempel-Ziv-Algorithmus.
Bevor eine Tabelle in eine Speicher schonende Form gebracht werden kann, muss sie entsprechend gekennzeichnet werden. Dies geschieht mit dem neuen Attribut "compess" in der Tabellendefinition ("CREATE TABLE ... COMPRESS YES") oder nachträglich mittels "ALTER TABLE ... COMPRESS YES".
Damit ist allerdings noch nichts gespart. Um später zu verifizieren, um wie viel der Platzbedarf der Tabelle durch die Komprimierung reduziert worden ist, verschaffen wir uns einen Überblick über die Lage vor der Komprimierung:
call admin_cmd('runstats on table yyy.xxxxx')
select npages,avgcompressedrowsize, avgrowcompressionratio, avgrowsize, pctrowscompressed from sysibm.systables where name='xxxxx'
Im konkreten Fall war npages=244026. Die Tabelle ist also bereits gefüllt, und das sollte auch vor der eigentlichen Komprimierung so sein, damit DB2 das Wörterverzeichnis erstellen kann. Mit dem werden dann die bereits vorhandenen Zeilen und später dazukommende Zeilen verdichtet.
Saturday, 16. December 2006
Was kann man durch die Komprimierung der Zeilen einer DB2-Tabelle gewinnen? Die Frage beantwortet "Inspect rowcompestimate". Das Verfahren ist zweischrittig:
db2 inspect rowcompestimate table tabname results keep filename;
db2inspf filename textfile.txt
Für die vorliegende Tabelle wurde eine Schätzung von 77% abgegeben, die sich als extrem nah an der tatsächlich erzielten Einsparung erwies.
And here are the results of the Venom jury - zu finden in der formatierten Datei textfile.txt, hier auszugsweise:
Thursday, 14. December 2006
... auf der kleinsten Platte. Selbst für große Datenbanken. Aber nur, wenn das DBMS über eine richtig starke Komprimierungsfunktion verfügt.
Das ist wahr für DB2 9. Das ist nicht wahr für DBMS wie Oracle oder den SQL Server.
Nun konnte ich bisher nur spekulieren, um wie viel der Platzbedarf einer Tabelle mit der DB2 9 Kompression reduziert werden kann. Laut IBM bis zu 70%, gemäß CW zwischen 45% und 75%. Wie hoch die Einsparung tatsächlich werden kann, hängt natürlich vom Design und Inhalt der zu komprimierenden Tabelle ab.
Da dem so ist, habe ich mit meiner größten lokal gespeicherten Tabelle einen Test gefahren. Diese Tabelle belegt ca. 1 GB auf der Harddisk. Mit der Kompression liefert DB2 auch eine Erweiterung der "Inspect"-Funktion, die die mögliche Reduktion des Platzbedarfs einer Tabelle schätzt. Für meine Tabelle hat Inspect eine Einsparung von 77% vorhergesagt. Überraschend viel. Und tatsächlich:
Nach Kompression verminderte sich der Größe meiner Tabelle auf 21,3% der unkomprimierten Tabelle.
Wednesday, 13. December 2006
So überschrieb Alan Zeichick seinen Blog-Eintrag zu 40 Jahre APL. Für mich ist Alan ein APL-Unbekannter. Nach eigener Aussage hat er Ende der 70er Jahre mit APL gearbeitet. Das kann aber nicht sehr ernsthaft gewesen sein: "I have no idea why we had APL on our System/370; it was never used for anything but fooling around."
Ich habe einige Ideen, wozu er und seine Kollegen hätten APL sinnvoll einsetzen können. Viele haben das ja gerade zu der Zeit getan. Dies ist übrigens auch heute noch eine wahre Aussage - nicht dass jemand jetzt auf die Idee kommt zu meinen, APL sei heute tot. Dem ist glücklicherweise nicht so.
Doch weiter zu Alan's Blog-Eintrag "Amazingly, IBM still sells APL tools today, 40 years later ...". Aber das sollte Dich doch nicht wirklich überraschen, Alan, denn Gutes hält sich ewig.
"You can perform complex calculations with only a few characters; designing algorithms to be concise (and often unreadable) is a marvelous talent." Talent hin oder her, die Fähigkeit, Algorithmen prägnant zu formulieren, ist auch eine typisch mathematische Eigenschaft. APL ist hier genauso lesbar oder unlesbar wie Mathematik. Und diese Präzision, die dem mathematischen Denken inne wohnt, ist Basis für die erstaunlichsten Fortschritte in den letzten Jahrhunderten.
"Sadly, I didn't spend enough time with APL to develop much skill. My "real" work involved PL/1, COBOL and FORTRAN, and noodling with APL was essentially a hobby." Dem kann man nur zustimmen. Tatsächlich ein trauriges Leben als ITler.
Tatsächlich startet Alan's Beitrag zur APL-Geburtstagsparty nicht sonderlich stark. Macht nichts, denn das Ende ist herrlich ("that article" meint den Beitrag zu APL in en.wikipedia.org):
"However, that article merely scratches the surface, and doesn't show the beauty and elegance of APL programming."
Dem ist nichts mehr hinzuzufügen.
Tuesday, 12. December 2006
Wie gesehen kann der AP127 noch nicht mit dem XML-Datentyp umgehen, er kennt ihn schlicht und ergreifend nicht.
Das bedeutet aber nicht, dass jedes SQL-Statement, in dem XML-Daten angefasst werden, zwangsläufig zu einem AP127-Fehler führt. Solange das Ergebnis einer Query keine Daten vom Typ XML (988) enthält, ist alles gut.
Hierzu ein Beispiel mit der Tabelle XMLCUSTOMER:
select c.cid from xmlcustomer c where xmlexists(''$i/customerinfo[name = "Kathy Smith"]' passing c.info as "i")
XMLEXISTS ist ein neues Prädikat. Es prüft, ob ein XQuery-Ausdruck ein nicht-leeres Ergebnis bringt. Im Ergebnis der Query selbst tauchen dagegen nur die Integer-Werte der Spalte CID auf.
Auch diese Query verleitet den AP127 nicht zu einer Fehlermeldung:
select X.* FROM XMLCUSTOMER C, XMLTable(''$cu/customerinfo'' PASSING C.INFO as "cu" COLUMNS "NAME" CHAR(20) PATH ''name'', "STREET" CHAR(20) PATH ''addr/street'', "CITY" CHAR(20) PATH ''addr/city'') AS X
Denn die Tabelle X enthält nur dem AP127 bekannte Datentypen. Dass in der Query irgendwo XML-Dokumente verarbeitet werden, bekommt er nicht mit. Gut so!
Nichtdestotrotz wäre es mehr als sinnvoll, den AP127 mit dem Datentyp 988 vertraut zu machen.
Monday, 11. December 2006
Eines der herausragenden neuen Features der neuen DB2-Version ist der XML-Datentyp und die daraus resultierende Möglichkeit, komfortabel mit XML-Dokumenten in DB2 zu arbeiten.
Nun besitzt APL2 mit dem AP127 eine direkte Schnittstelle zu DB2, ohne Umwege über Interfaces wie ODBC. Nachdem ich auch auf diesem Rechner DB2 9 installiert habe, hat es mich geradezu in den Fingern gejuckt, mal auf XML-Daten von APL2 aus zuzugreifen.
Das Ergebnis zeigt, dass noch Einiges zu tun ist. Dazu ein erstes Beispiel:
 Ich nehme die Tabelle XMLCUSTOMER aus der DB2 Sample-Datenbank. Sie hat zwei Spalten, CID und INFO. CID ist vom Typ Integer, INFO vom Typ XML.
Ein einfaches 'Select * from XMLCUSTOMER' mittels AP127 ergibt einen AP2X127105 "SQL DATATYPE 989 (COLUMN INFO) NOT SUPPORTED BY AP 127". Das ist nicht wirklich überraschend.
Der neue Datentyp muss also dem AP127 noch vorgestellt werden.
Sunday, 10. December 2006
Seltsam, das war mir vorher noch nicht aufgefallen: Der DB2-Befehl "list database directory" ergibt unter Windows leicht unterschiedliche Ausgaben:
Bis Version 8.2 findet man für lokale Datenbanken unter "Lokales Datenbankverzeichnins" sowohl eine Angabe zum Laufwerk als auch zum Verzeichnis. Mit Version 9.1 wird nur das Laufwerk angegeben.
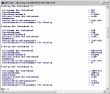 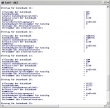
Naja, mich tröstet da nur, dass man beim "create database ..." auch nur einen Laufwerksbuchstaben angeben kann. Das Verzeichnis wird von DB2 vorgegeben.
Und dann gibt es noch zwei neue Zeilen pro gelisteter Datenbank: "Hostname des Alternativservers" und "Portnummer des Alternativservers".
Friday, 8. December 2006
Will man all die schönen neuen Features der DB2 9 nutzen, muss man kräftig Lizenzen ordern und registrieren. Im Einzelnen gibt es folgende Zusatzoptionen:
- das pureXML Feature
- das Storage Optimization Feature
- das Performance Optimization Feature
- das Advanced Access Control Feature
- das Database Partitioning Feature (DPF)
- und last but not least dei Homogeneous Federation
Die erste Lizenz brauche ich zum Tö... äh zum Arbeiten mit dem neuen XML-Datentyp, hinter der zweiten steckt die neue Venom-Kompression. Mit Advanced Access Control ist LBAC gemeint, eine weitere positiv bewertete Neuerung. Advanced, da es natürlich schon lange die Möglickeit zur Vergabe von Berechtigungen auf Objektebene (z.B. Tabellen oder Views) gibt.
Die folgenden Optionen gab es auch schon in den Vorgänger-Versionen: Das DPF dient zur Verteilung von Datenbanken über mehrere Rechner, die Performance Optimization fasst den Query Patroller und den Performance Expert zusammen. Das Homogeneous Federation Feature ermöglicht den Zugriff auf ferne DB2 und Informix-Datenquellen, für alles andere muss man den Websphere Information Server erwerben.
|
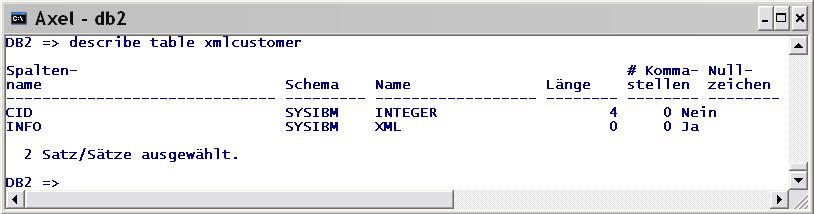 Ich nehme die Tabelle XMLCUSTOMER aus der DB2 Sample-Datenbank. Sie hat zwei Spalten, CID und INFO. CID ist vom Typ Integer, INFO vom Typ XML.
Ich nehme die Tabelle XMLCUSTOMER aus der DB2 Sample-Datenbank. Sie hat zwei Spalten, CID und INFO. CID ist vom Typ Integer, INFO vom Typ XML.

 ap127
ap127