Thursday, 4. January 2007
Und noch mehr "Data flow enhancements":
"Saving flows as images: You can save flow diagrams (data flows, control flows, and so on) as image files."
 Einfach rechter Mausklick auf dem Panel (dem "Erstellungsbereich" des Daten- oder Steuerungsflusses), "Datei" und "Als Imagedatei speichern ..." auswählen, ausfüllen und los.
Ein hilfreiches Feature für Dokumentationswütige und Leute, die ihre Elaborate gerne publizieren. Im Ernst: wenn es diese Möglichkeit ab jetzt nicht geben würde, hätte ich sie sicher demnächst schmerzlich vermisst.
"Expanded variable support: In data flows and control flows, several new properties can be set as variables, and the SQL Expression Builder includes a Variables section."
In den Eigenschaften eines Datenflusses gilt dies für die zwei (evtl.) neuen Felder für "Tabellenbereiche" sowie für Felder einiger Operatoren. Im Steuerungfluss trifft das wohl auf den einen oder anderen Operator zu. Zu einer sicheren Aussage über solche Erweiterungen fehlt mir der Vergleich mit der Version 9.1. Die habe ich ja hier mit dem Refresh überbügelt.
Offensichtlich ist der erweiterte "variable support" im SQL Expression Builder. Dieser kommt als "SQL Code Builder", "SQL Condition Builder" oder anders überall dort zum Einsatz, wo SQL-Ausdrücke erstellt werden sollen. Hier gibt es jetzt auf der rechten Seite eine neue Box unter der Überschrift "Variablen".
Wednesday, 3. January 2007
Dies sind drei weitere Neuerungen aus dem Bereich "Data flow enhancements":
"Table source filtering: You can apply a WHERE clause condition to the data that is read in from a source table."
Einfach praktisch, das erspart einen gesonderten Operator auf der Arbeitsfläche. Im Tabellenquelle-Operator gibt es dazu in der Markmalsicht die neue Seite "Bedingung WHERE".
"Commit intervals: For SQL Insert operations, you can specify a commit interval in the table target operator."
Dahinter verbirgt sich das neue Eingabefeld "Commitintervall" auf der "allgemeinen" Eigenschaftenseite des Tabellenziel-Operators. Hier kann die Anzahl eingefügter Zeilen spezifiziert werden, nach denen ein Commit ausgeführt wird.
Da musste aber einiges an der Code-Generierung für das Insert geändert werden.
"Exploitation of the DB2 Database Partitioning Feature (DPF): To improve the performance of data flows and certain data flow operators (such as distinct and splitter operators), the SQL Warehousing Tool generates partition-aware code based on properties specified in the data flow."
Ich denke, dazu ist die Check-Box "DB2-Datenbankpartitionierungsfunktion (DPF) verwenden" vorgesehen.
Das gleiche gilt für die Merkmalsicht-Seite "Einstellungen für die Zwischenspeichertabelle" der Operatoren "Eindeutig" (Distinct), "Verteilerprozess" (Splitter) und "Schlüsselsuche" sowie die Seite "Partitionierungsoptionen" der Operators "Massenladeziel" und "Dateiimport" (wobei sich mir nicht erschließt, was genau unter dem Feldnamen "Partitionierungspartitionen" zu verstehen ist).
Dies wird die lange Antwort zu dieser kurzen Frage. Lang, da die Liste der Neuerungen und Änderungen recht umfangreich ist mit 34 Einträgen. Wie obiger Titel vermuten lässt, wird sich die Antwort wohl auf mehrere Blogeintäge verteilen.
Die meisten Änderungen findet man unter der Überschrift "SQL Warehousing Tool features" und dort zum Thema "Data flow enhancements". Und hier geht es gleich mit einer sehr sinnvollen und hilfreichen Erweiterung los:
"Flat file discovery: You can sample a file in the file import operator and automatically generate its schema, instead of manually defining columns and data types." Konkret ist hier der neue Knopf "Dateiformat generieren" auf der Dateiformat-Seite des Dateiimport-Operators gemeint. Damit wird ein Dialog gestartet, in dessen Verlauf die Liste der zu importierenden Felder mit wenigen Eingaben komfortabel generiert werden kann.
Diese Erweiterung ist ohne Frage sehr hilfreich. Ich hatte einen solche Unterstützung bereits vermisst, da z.B. Access seit langem über einen solchen Assistenten zur Erstellung von csv-Dateien verfügt.
Tuesday, 2. January 2007
Hier die kurze Antwort auf die kurze Frage: Sehr viel für ein hundertstel Upgrade.
Wie bereits an anderer Stelle ausgeführt, ist der wichtigste Grund für den Refresh die Einbindung einiger neuen Features der DB2 9. Im DB2 Magazine heißt es dazu:
"A DWE 9.1.1 refresh available this quarter upgrades the DWE package to DB2 9 and addresses requests from early DWE 9.1 adopters. DB2 9 includes a number of critical enhancements in its role as the underlying engine for DWE, including self-tuning memory management, range partitioning, and row compression."
Laut "What's New in DWE 9.1.1" in den Release Notes (Seite 2-4) werden neben der DB2 9-Unterstützung Verbesserungen in folgenden Bereichen ausgeliefert:
- Installation and configuration features
- SQL Warehousing Tool features
- Administration Console features
- Data mining features
Hinter diesen Überschriften verstecken sich insgesamt 34 einzelne Neuerungen und Verbesserungen.
Das ist doch nicht normal für ein ein Refresh.
... der DWE auf die 9.1.1 bleibt neben den Post-Installationsaufgaben noch die Aktualisierung einiger Tabellen der SQW-Steuerdatenbank. Bei einer Neuinstallation der DWE 9.1.1 braucht dieser Migrationsschritt natürlich nicht durchgeführt werden.
Diese " erforderliche Migrationstask" besteht aus der Ausführung zweier SQL-Scripts: addConstraints.sql und upd_unitsum.sql.
Diese Dateien wurden von der Installationsroutine für die DWE-Verwaltungskonsole in das Verzeichnis DWE\DWEAdmin kopiert und sollten dort auch im DB2-Befehlsfenster ausgeführt werden.
Es ist eigentlich eine triviale Bemerkung, dass man sich vorher mit der betreffenden Datenbank verbinden muss (db2 connect to SQWCTRL). Es war auch keine Überraschung, dass ich danach erst mal folgenden freundlichen Hinweis bekam:
"SQL5035N Die Datenbank muss auf das aktuelle Release umgestellt werden.
SQLSTATE=55001"
Monday, 1. January 2007
Also doch! Zum Upgrade der DWE von Version 9.1 auf 9.1.1 sollte man auch die "Anwendungsserverkomponenten" einbeziehen. Als zu installierende Komponente braucht nur die "DWE-Verwaltungskonsole" ausgewählt werden. Die Zusammenfassung zeigt daraufhin, dass damit auch die neuen Miningblox installiert werden.
Während der folgenden Installation werden unterhalb des DWE-Verzeichnisses zwei neue Verzeichnisse angelegt: "Miningblox" und "config".
Die Miningblox sind damit allerdings noch nicht endgültig installiert. Gemäß Installation Guide bzw. der readme.txt im Verzeichnis "Miningblox" ist hier noch eine Post-Installations-Aufgabe zu erledigen.
Was das "config"-Verzeichnis angeht, steckt hinter seiner Existenz eine Verbesserung des Konfigurationstools:
"DWE configuration tool is installed: The configuration tool is now installed on the DWE application server so you can run it anytime to update the initial configuration." (s. "What's New in DWE 9.1.1" in readme911.pdf) Mit der Version 9.1 musste der Konfigurationsdialog noch aus dwecd\config heraus gestartet werden. Aus der config.exe wurde nun eine config.bat, die während der Installation erstellt wird.
Der DWE Integrated Install erledigt fast die komplette Installation der Data Warehouse Edition seit Version 9.1. Aber eben nur fast:
Auf der Seite " DB2 Data Warehouse Edition 9.1.1, downloading Developer/Enterprise Ed. (Windows)" findet man zur "Part number" C95YUML folgenden sinnvollen Hinweis:
"DB2 Data Warehouse Edition V9.1 Quick Start. This image contains the Quick Start Guide, which provides a high-level overview of the installation process. This image also contains DWE books in PDF format. The integrated installation program does not install this image." Also habe ich die Dateien manuell installiert. Dazu habe ich 16 Dateien aus 13 Verzeichnissen kopiert, soweit vorhanden die deutsche Version eines pdf. Eine Solche gibt es in den meisten Fällen, aber ausgerechnet bei den Dokumenten zum Mining fehlt eine deutsche Übersetzung - und nicht nur diese: Mining auf chinesisch lässt auch noch auf sich warten.
Der manuelle Aufwand lohnt sich: Das Image C95YUML enthält Handbücher zur Installation, zum Design Studio, zur Administrationskonsole, zum Mining sowie zu den neue Miningblox, das Tutorial und weitere Dokumentationen.
Saturday, 30. December 2006
Das gab es auch schon für die DWE Version 9.1: die " Post-Installation tasks". Dazu gehört die Konfiguration diverser DWE-Komponenten: Intelligent Miner, Alphablox, Application Server und das Information Center (s.a. DWE Installation Guide, Chapter 7).
Ich habe mir bisher diese Tätigkeiten geschenkt, da ich sie bereits bei der Installation der Version 9.1 erledigt habe, und sich durch die neuen 9.1.1-Komponenten an der Konfiguration von Alphablox und dem WAS nichts verändert haben sollte. Die "Post-Installation Task" für den Miner besteht unter Windows sowieso nur im " Enabling" von Datenbanken für das Mining.
Zusätzlich zu diesen Aufgaben kommt noch für die 9.1.1 die Installation der Miningblox und das Upgrading der DWE Control Datenbank.
Als weitere "Post-Installation task" kann man auch die folgende Empfehlung aus dem Installation Guide (S.39) betrachten:
"To verify that the installation was successful, check the log files listed in Appendix B, “Log file locations,” on page 53. In the main installation log file dweinstall.log, check the lines that contain keywords such as err, Exception, wrn for errors and warnings." Dem bin ich ausnahmsweise mal nachgekommen, da mein Upgrade nicht ganz perfekt war. Im logs-Verzeichnis meiner DWE-Installation war tatsächlich nur dweinstall.log mit einem aktualisierten Zeitstempel versehen. Die anderen Installationslogs waren - wie zu erwarten war - unverändert.
Thursday, 28. December 2006
Die eigentliche Rechtfertigung für die seit Anfang dieses Monats verfügbare Data Warehouse Edition 9.1.1 ist die Unterstützung einiger Neuerungen der DB2 9. Aber nicht nur deshalb habe ich meine Datenbankversion unabhängig und als Erstes aktualisiert.
Da sich außerdem bei Alphablox und dem Websphere Application Server nichts verändert hat, müssen nur noch zum Upgrade auf die DWE Version 9.1.1 die neuen Komponenten des SQW, des Intelligent Miner und der DWE Administration installieren werden. Das erledigt die aktuelle Variante des Integrated Installers.
Hier brauchen also unter "Implementierungsoptionen" die "Anwendungsserverkomponenten" nicht ausgewählt werden ( 01.01.2006: tatsächlich muss eine Anwendungsserverkomponente - die DWE Verwaltungskonsole - aktualisiert werden). Die sind ja bereits installiert. Das gleiche gilt in diesem Fall für DB2, es kann daher eine "vorhandene DB2-Kopie" verwendet werden.
In der Auswahl der DWE-Komponenten können dementsprechend serverseitig DB2 und der Query Patroller abgewählt werden. Das Gleiche gilt für den Client. Unter Dokumentation kann man auf die "Alphablox Informationszentrale" verzichten. Eigentlich kann man das auch für die Cube Views-Komponenten abwählen, sicherheitshalber habe ich sie aber mitgenommen.
Die folgende Installation dauert eine Weile, immerhin werden 823 MB Daten bewegt.
Sunday, 12. November 2006
Da war ich doch etwas voreilig mit meinem Wunsch nach einer Möglichkeit, Mining-Modelle im Design Studio zu verwalten.
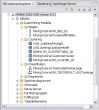 Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.
Und nicht nur das: Ein rechter Mausklick auf ein Modell öffnet ein Menü mit den Einträgen "Öffnen", "Löschen", "Umbenennen" und "Exportieren".
Sunday, 29. October 2006
Von Mining-Operatoren wie z.B. dem "Clusterer" werden automatisch Mining-Modelle erstellt und in der Datenbank gespeichert. So ein Modell kann dann im Scorer ausgewählt werden. Bei dieser Auswahl kann man dann sehen, welche Modelle überhaupt erstellt wurden. Da war dann in meinem Fall noch das eine oder andere experimentelle Modell darunter.
Nur, wo kann ich solche nicht verwendete Modelle löschen. Oder allgemeiner: Wo kann ich Mining-Modelle verwalten?
Einfache Frage, einfache Antwort: In der Ausführungsdatenbank und dort in der Tabelle IDMMX.CLUSTERMODELS. Dies ist übrigens eine der Tabellen, die beim " Enable for Data Mining" angelegt werden.
Zur Verwaltung der Modelle steht also der komplette SQL-Funktionsumfang zur Verfügung.
Trotz alles SQL-Möglichkeiten wäre es sicher sinnvoll, wenn Mining-Modelle direkt im Design Studio in bewährter Art und Weise verwaltet werden könnten (23.11.2006: was auch tatsächlich angeboten wird, wenn auch an etwas unerwarteter Stelle).
Saturday, 28. October 2006
Bevor man Data Mining in DB2 betreiben kann, muss vorher die jeweilige Datenbank dafür vorbereitet werden. Dies geschieht mit
idmenabledb ... fenced dbcfg
im DB2 Befehlsfenster (wobei an Stelle von ... natürlich der Datenbankname stehen sollte).
Damit wird ein Schema erstellt, unter dem dann einige Tabellen und eine Vielzahl von Anwendungsobjekten (datentypen, Funktionen, Prozeduren und Methoden) angelegt werden.
Im Design Studio gibt es hierzu (noch) keinen Eintrag im Kontextmenu der Datenbank, so wie es das die Anlage der OLAP-Objekte vorgesehen ist. (23.11.2006: Tatsächlich findet man solch einen Eintrag im Datenbankexplorer)
Eine der hilfreichsten von vielen nützlichen Funktionen im Design Studio ist "In Modell speichern". Sie ist jeweils unter "Virtuelle Tabelle" in den Eigenschaften der Ein- und Ausgabeports verfügbar. So kann ganz einfach eine durch einen Operator erstellte Ausgabe sofort im Modell als Tabelle widerspiegelt werden. Diese Tabelle kann ich dann z.B. als Tabellenziel am Ende des Flusses verwenden.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Um das alles ein wenig abzukürzen: Im Falle des Scorer geht das schief.
"Schiefgagangen" vollständig lesen
Hier sind zwei der Kleinigkeiten, die mir das Entwickeln eines Minig-Flusses erleichtern:
Friday, 27. October 2006
Ein Fluss muss nicht wie der andere sein.
Zumindest ist das im Design Studio recht offensichtlich. Hat man einige Datenflüsse und Minig-Flüsse erstellt, sieht man recht schnell, dass dahinter wohl unterschiedliche Entwicklerteams stecken. Das zeigt sich an vielen Kleinigkeiten.
Und auch an einer Funktion, die bisher nur dem Mining-Fluss-Entwickler zur Verfügung steht: "Bis zu diesem Schritt ausführen ...". Genial ...
Rechte Maustaste drücken auf einem Operator in Mining-Fluss und den Punkt im Kontextmenü auswählen. Der Rest ist selbstredend. Es können also beliebige Teilflüsse getestet werden, natürlich ohne dass der Mining-Fluss vollständig sein muss.
Dieses Feature wäre auch für das Erstellen und Test von Datenflüssen hilfreich. Wieder ein Feature für zukünftige DWE-Versionen.
|
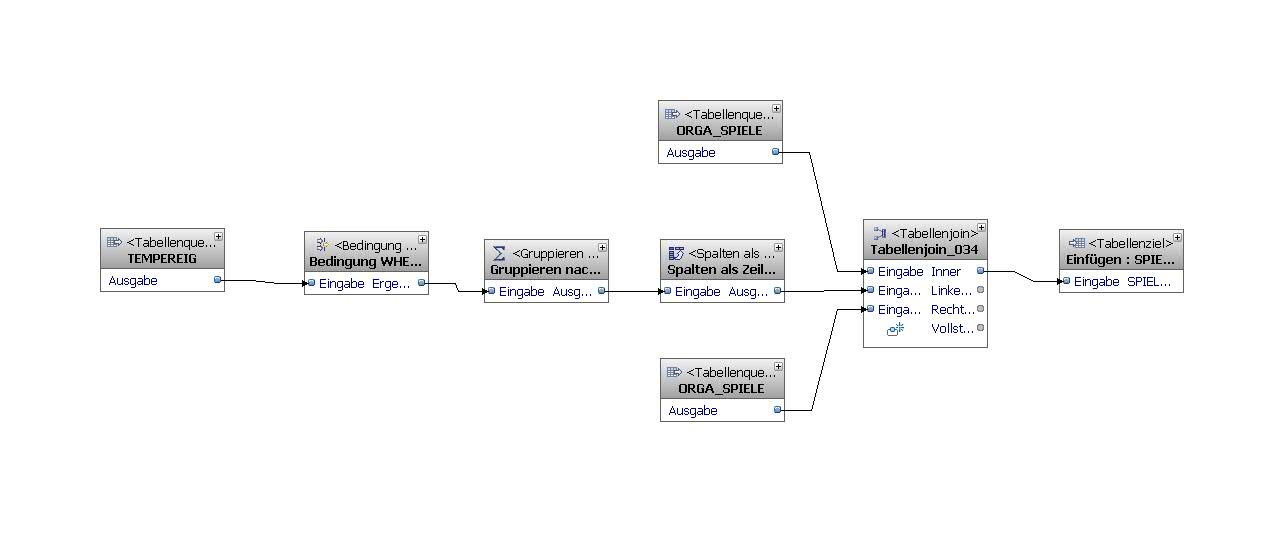 Einfach rechter Mausklick auf dem Panel (dem "Erstellungsbereich" des Daten- oder Steuerungsflusses), "Datei" und "Als Imagedatei speichern ..." auswählen, ausfüllen und los.
Einfach rechter Mausklick auf dem Panel (dem "Erstellungsbereich" des Daten- oder Steuerungsflusses), "Datei" und "Als Imagedatei speichern ..." auswählen, ausfüllen und los.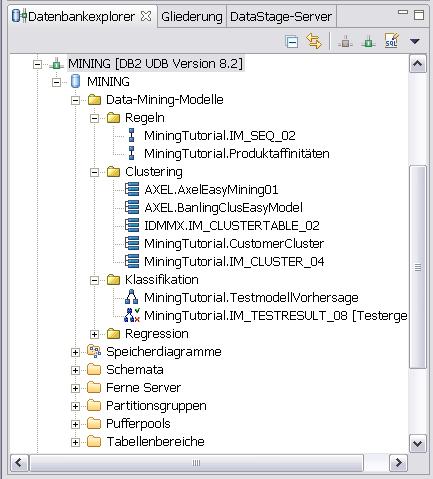 Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden.
Der Wunsch ist wohl berechtigt gewesen, war aber bereits erfüllt. Hätte ich mal vorher die Hilfe zum Mining in der DWE zu Rate gezogen. Denn dort steht, dass Mining-Modelle, die von diversen Operatoren erzeugt werden, im Datenbankexplorer unter der jeweiligen Datenbank und dort unter "Data-Mining-Modelle" aufgeführt werden. Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.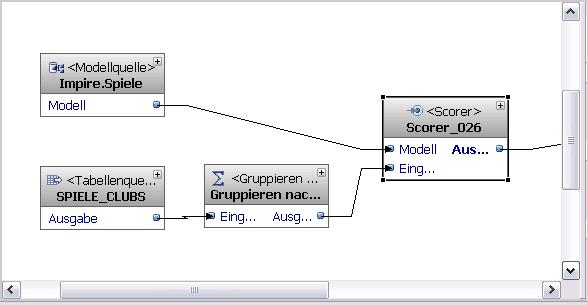

 ap127
ap127