Sunday, 24. December 2006
Nachdem meine erste Zeilenkomprimierung einer Tabelle eine hohe Verdichtungsrate aufgrund suboptimalen Designs erbrachte, fragt sich nun, ob der Tabelle mit verbesserter Definition ein ähnlich hohes Sparpotenzial innewohnt.
Natürlich konnte ich nicht wieder 78% erwarten, aber die Vorhersage (inspect rowcompestimate) war dennoch erfreulich:
Prozentsatz der durch die Komprimierung gesparten Seiten: 58
Prozentsatz der durch die Komprimierung gesparten Byte: 58
Prozentsatz der Zeilen, die wegen geringer Zeilengröße nicht für die Komprimierung ausgewählt werden können: 0
Größe des Komprimierungswörterverzeichnisses: 45824 Byte.
Größe des Erweiterungswörterverzeichnisses: 32768 Byte.
Also weniger als die Hälfte des Platzes der unkomprimierten Tabelle, nicht schlecht!
Und tatsächlich: Statt 107541 4K-Seiten belegt die Tabelle nach "alter table ... compress yes" und dem Reorg nur noch 44171 Seiten. Dies ist eine Verdichtung auf 41%.
Die Prognose durch rowcompestimate war wieder sehr treffend. Man kann sich wohl darauf verlassen.
Wednesday, 20. December 2006
Meine Tabelle zum Experimentieren mit der Venom-Komprimierung hat einige Design-Schwächen, die zu der überraschend hohen Kompressionsrate geführt haben.
Die Unachtsamkeit beim der Definition des Tabellen-Layouts lag darin, dass die meisten Spalten als char mit konstanter Länge vorgegeben wurden. Darunter sind Felder für die Aufnahme von Namens- und Adressdaten, deren Längen so gewählt wurde, dass der längste Nachname oder der längste Straßenname komplett aufgenommen werden konnte.
Damit wird viel Speicherplatz mit rechtsbündig auffüllenden Leerstellen verschwendet. Die Mehrzahl dieser Spalten sind mit weniger als 20% Sinn tragender Daten gefüllt. Ein Defizit, das durch die neue Zeilenkomprimerung ohne großen Aufwand gut kaschiert werden konnte.
Aber es geht doch auch anders, auf klassischem Weg: sorgfältigeres Design. So konsumiert z.B. eine als varchar(50) statt char(50) definierte Spalte im vorliegenden Fall 80% weniger Speicherplatz.
Zusammen mit entsprechenden Änderungen für Spalten mit stark unterschiedlich langen Zeichenketten ergibt das eine Reduktion der durchschnittlichen Zeilenlänge um 56% (select avgrowsize from sysibm.systables where name= tabellename). Für die absolute Größe der beiden Tabellen bedeutet das 244026 4K-Pages der Originaltabelle gegenüber 107541 Pages der Tabelle mit den geänderten Datentypen.
Manchmal macht eben eine Komprimierung per Hand noch vor Einsatz aufwändiger Algorithmen Sinn.
Tuesday, 19. December 2006
Überraschend und auch nicht überraschend.
Gemeint ist hier der Zugriff auf zeilenkomprimierte DB2 9 Tabellen. Denn das Selektieren von Daten bedeutet eben nicht nur Lesen von Bits und Bytes von Platte oder aus dem Datenbank-Buffer, sondern auch noch das rechenintensive Dekomprimieren der extrahierten Daten. Letzteres belastet den Prozessor mit Mehrarbeit.
Andererseits sinkt durch den geringere Größe der komprimierten Daten der Aufwand für I/O. Darüberhinaus kann aufwändiger I/O durch den wesentlich schnelleren Griff in den Buffer ersetzt werden, denn durch die Komprimierung kann dieser größere Teile der Tabelle im RAM vorhalten.
Es ist also ein Geben und Nehmen. Allgemein wird keine konkrete Vorhersage zu der Auswirkung der Zeilenkomprimierung einer Tabelle auf die Performance eines Zugriffs möglich sein. Bisherige Erfahrungen gehen davon aus, dass sich die Bearbeitungszeit für SQL-Statements nicht verschlechtert, und wenn Unterschiede festzustellen sind, dann zugunsten der komprimierten Variante.
Ich habe also erwartet, dass sich für meinen Test die Performance möglicherweise geringfügig verbessert. Dieser besteht ausschließlich aus Select-Statements, die einen unter Verwendung von Indexspalten, die anderen erfordern einen Scan der Tabelle.
Monday, 18. December 2006
... so geht's. Genau genommen ist das Thema: Die Zeilen einer Tabelle unter Verwendung eines Verzeichnisses komprimieren. Das von DB2 dazu verwendete Kompressionsverfahren namens "Venom" arbeitet dabei mit dem Lempel-Ziv-Algorithmus.
Bevor eine Tabelle in eine Speicher schonende Form gebracht werden kann, muss sie entsprechend gekennzeichnet werden. Dies geschieht mit dem neuen Attribut "compess" in der Tabellendefinition ("CREATE TABLE ... COMPRESS YES") oder nachträglich mittels "ALTER TABLE ... COMPRESS YES".
Damit ist allerdings noch nichts gespart. Um später zu verifizieren, um wie viel der Platzbedarf der Tabelle durch die Komprimierung reduziert worden ist, verschaffen wir uns einen Überblick über die Lage vor der Komprimierung:
call admin_cmd('runstats on table yyy.xxxxx')
select npages,avgcompressedrowsize, avgrowcompressionratio, avgrowsize, pctrowscompressed from sysibm.systables where name='xxxxx'
Im konkreten Fall war npages=244026. Die Tabelle ist also bereits gefüllt, und das sollte auch vor der eigentlichen Komprimierung so sein, damit DB2 das Wörterverzeichnis erstellen kann. Mit dem werden dann die bereits vorhandenen Zeilen und später dazukommende Zeilen verdichtet.
Saturday, 16. December 2006
Was kann man durch die Komprimierung der Zeilen einer DB2-Tabelle gewinnen? Die Frage beantwortet "Inspect rowcompestimate". Das Verfahren ist zweischrittig:
db2 inspect rowcompestimate table tabname results keep filename;
db2inspf filename textfile.txt
Für die vorliegende Tabelle wurde eine Schätzung von 77% abgegeben, die sich als extrem nah an der tatsächlich erzielten Einsparung erwies.
And here are the results of the Venom jury - zu finden in der formatierten Datei textfile.txt, hier auszugsweise:
Thursday, 14. December 2006
... auf der kleinsten Platte. Selbst für große Datenbanken. Aber nur, wenn das DBMS über eine richtig starke Komprimierungsfunktion verfügt.
Das ist wahr für DB2 9. Das ist nicht wahr für DBMS wie Oracle oder den SQL Server.
Nun konnte ich bisher nur spekulieren, um wie viel der Platzbedarf einer Tabelle mit der DB2 9 Kompression reduziert werden kann. Laut IBM bis zu 70%, gemäß CW zwischen 45% und 75%. Wie hoch die Einsparung tatsächlich werden kann, hängt natürlich vom Design und Inhalt der zu komprimierenden Tabelle ab.
Da dem so ist, habe ich mit meiner größten lokal gespeicherten Tabelle einen Test gefahren. Diese Tabelle belegt ca. 1 GB auf der Harddisk. Mit der Kompression liefert DB2 auch eine Erweiterung der "Inspect"-Funktion, die die mögliche Reduktion des Platzbedarfs einer Tabelle schätzt. Für meine Tabelle hat Inspect eine Einsparung von 77% vorhergesagt. Überraschend viel. Und tatsächlich:
Nach Kompression verminderte sich der Größe meiner Tabelle auf 21,3% der unkomprimierten Tabelle.
Tuesday, 12. December 2006
Wie gesehen kann der AP127 noch nicht mit dem XML-Datentyp umgehen, er kennt ihn schlicht und ergreifend nicht.
Das bedeutet aber nicht, dass jedes SQL-Statement, in dem XML-Daten angefasst werden, zwangsläufig zu einem AP127-Fehler führt. Solange das Ergebnis einer Query keine Daten vom Typ XML (988) enthält, ist alles gut.
Hierzu ein Beispiel mit der Tabelle XMLCUSTOMER:
select c.cid from xmlcustomer c where xmlexists(''$i/customerinfo[name = "Kathy Smith"]' passing c.info as "i")
XMLEXISTS ist ein neues Prädikat. Es prüft, ob ein XQuery-Ausdruck ein nicht-leeres Ergebnis bringt. Im Ergebnis der Query selbst tauchen dagegen nur die Integer-Werte der Spalte CID auf.
Auch diese Query verleitet den AP127 nicht zu einer Fehlermeldung:
select X.* FROM XMLCUSTOMER C, XMLTable(''$cu/customerinfo'' PASSING C.INFO as "cu" COLUMNS "NAME" CHAR(20) PATH ''name'', "STREET" CHAR(20) PATH ''addr/street'', "CITY" CHAR(20) PATH ''addr/city'') AS X
Denn die Tabelle X enthält nur dem AP127 bekannte Datentypen. Dass in der Query irgendwo XML-Dokumente verarbeitet werden, bekommt er nicht mit. Gut so!
Nichtdestotrotz wäre es mehr als sinnvoll, den AP127 mit dem Datentyp 988 vertraut zu machen.
Monday, 11. December 2006
Eines der herausragenden neuen Features der neuen DB2-Version ist der XML-Datentyp und die daraus resultierende Möglichkeit, komfortabel mit XML-Dokumenten in DB2 zu arbeiten.
Nun besitzt APL2 mit dem AP127 eine direkte Schnittstelle zu DB2, ohne Umwege über Interfaces wie ODBC. Nachdem ich auch auf diesem Rechner DB2 9 installiert habe, hat es mich geradezu in den Fingern gejuckt, mal auf XML-Daten von APL2 aus zuzugreifen.
Das Ergebnis zeigt, dass noch Einiges zu tun ist. Dazu ein erstes Beispiel:
 Ich nehme die Tabelle XMLCUSTOMER aus der DB2 Sample-Datenbank. Sie hat zwei Spalten, CID und INFO. CID ist vom Typ Integer, INFO vom Typ XML.
Ein einfaches 'Select * from XMLCUSTOMER' mittels AP127 ergibt einen AP2X127105 "SQL DATATYPE 989 (COLUMN INFO) NOT SUPPORTED BY AP 127". Das ist nicht wirklich überraschend.
Der neue Datentyp muss also dem AP127 noch vorgestellt werden.
Sunday, 10. December 2006
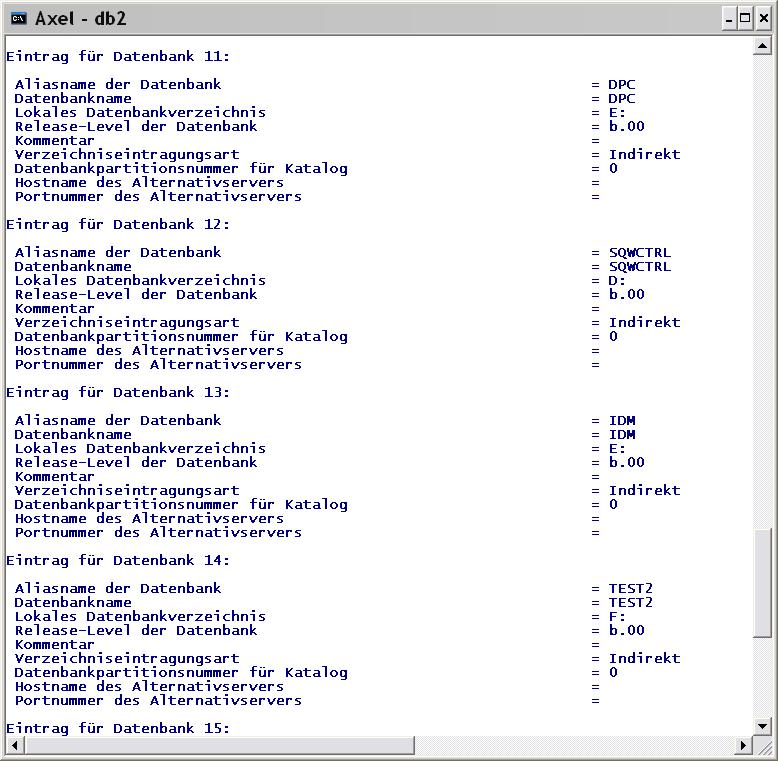
Seltsam, das war mir vorher noch nicht aufgefallen: Der DB2-Befehl "list database directory" ergibt unter Windows leicht unterschiedliche Ausgaben:
Bis Version 8.2 findet man für lokale Datenbanken unter "Lokales Datenbankverzeichnins" sowohl eine Angabe zum Laufwerk als auch zum Verzeichnis. Mit Version 9.1 wird nur das Laufwerk angegeben.
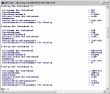 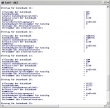
Naja, mich tröstet da nur, dass man beim "create database ..." auch nur einen Laufwerksbuchstaben angeben kann. Das Verzeichnis wird von DB2 vorgegeben.
Und dann gibt es noch zwei neue Zeilen pro gelisteter Datenbank: "Hostname des Alternativservers" und "Portnummer des Alternativservers".
Friday, 8. December 2006
Will man all die schönen neuen Features der DB2 9 nutzen, muss man kräftig Lizenzen ordern und registrieren. Im Einzelnen gibt es folgende Zusatzoptionen:
- das pureXML Feature
- das Storage Optimization Feature
- das Performance Optimization Feature
- das Advanced Access Control Feature
- das Database Partitioning Feature (DPF)
- und last but not least dei Homogeneous Federation
Die erste Lizenz brauche ich zum Tö... äh zum Arbeiten mit dem neuen XML-Datentyp, hinter der zweiten steckt die neue Venom-Kompression. Mit Advanced Access Control ist LBAC gemeint, eine weitere positiv bewertete Neuerung. Advanced, da es natürlich schon lange die Möglickeit zur Vergabe von Berechtigungen auf Objektebene (z.B. Tabellen oder Views) gibt.
Die folgenden Optionen gab es auch schon in den Vorgänger-Versionen: Das DPF dient zur Verteilung von Datenbanken über mehrere Rechner, die Performance Optimization fasst den Query Patroller und den Performance Expert zusammen. Das Homogeneous Federation Feature ermöglicht den Zugriff auf ferne DB2 und Informix-Datenquellen, für alles andere muss man den Websphere Information Server erwerben.
Thursday, 7. December 2006
Bevor ich die frisch verfügbare DWE 9.1.1 installiere, werde ich zuerst meine DB2 nach Version 9.1 migrieren. Dies ist mehr als angesagt, da die wesentliche Neuigkeit der DWE 9.1.1 die Unterstützung der DB2 9.1 ist.
 Doch für das Upgrade der DB2 müssen noch einige Vorbereitungen getroffen werden. Daran erinnert das 9.1 Setup bevor es loslegt. Und es empfiehlt sich tatsächlich nachzuprüfen, ob auch alle lokalen Datenbanken auf die neue DBMS-Version migriert werden können. Das erledigt das DB2-Utility "db2ckmig" mit
db2ckmig databasename -L logdateiname
für eine Datenbank oder mit
db2ckmig -e -L logdateiname
für alle lokalen Datenbanken.
Und tatsächlich: Das Tool findet eine Uralt-Datenbank, die sich klammheimlich der Migration von 8.1 auf 8,2 entzogen hatte. Die muss also vorher erst noch nach 8.2 migriert werden ("db2 migrate database databasename").
Saturday, 28. October 2006
Bevor man Data Mining in DB2 betreiben kann, muss vorher die jeweilige Datenbank dafür vorbereitet werden. Dies geschieht mit
idmenabledb ... fenced dbcfg
im DB2 Befehlsfenster (wobei an Stelle von ... natürlich der Datenbankname stehen sollte).
Damit wird ein Schema erstellt, unter dem dann einige Tabellen und eine Vielzahl von Anwendungsobjekten (datentypen, Funktionen, Prozeduren und Methoden) angelegt werden.
Im Design Studio gibt es hierzu (noch) keinen Eintrag im Kontextmenu der Datenbank, so wie es das die Anlage der OLAP-Objekte vorgesehen ist. (23.11.2006: Tatsächlich findet man solch einen Eintrag im Datenbankexplorer)
Monday, 23. October 2006
Diese Ankündigung habe ich noch nicht bei ibm.com gefunden. Daher gibt es hier auch keinen Link, und daher konnte ich keine Details nachsehen. Einige Fragen bleiben also offen, spätestens bis ich die Version 9.1.1 installiert habe.
Das wird dann auch nicht mehr solange auf sich warten lassen: am 1.12. steht der Refresh zum Download bereit, also noch im 4.Quartal, so wie prognostiziert.
Die wesentliche Neuerung dieser Hundertstel-Version ist die Einbindung der aktuellen DB2-Version 9.1. Dies hätte möglicherweise auch mit der DWE 9.1 funktioniert, aber mit der 9.1.1 ist es nun offiziell. Und man weiß ja nie, was so passieren kann.
Damit stehen nun der DWE alle neuen Features der DB2 9 wie
- Self-Tuning Memory Management
- Table (Range) Partitioning und
- Table (Row) Compression
zur Verfügung. So zu lesen in der Ankündigung. Mal sehen, wie sich dies im SQW niederschlägt.
... hat IBM nach eigenen Aussagen in die Entwicklung von DB2 9 gesteckt. In Sachen Performance scheint sich diese Investition gelohnt zu haben, zumindest aus Sicht des Marketings. Danach hält DB2 9 nun eine dreifache Benchmark-Krone:
"A key measure of the impact that these new technologies are having is the “big three” industry benchmark records (TPC-C, TPC-H and SAP SD) – collectively known as the Database performance triple crown."
...
"IBM today announced that with the introduction of DB2 9 it has set new record marks in each and has now won the “triple crown” of database performance for an unprecedented third time."
Für die TPC-Ergebnisse schlage man ebendort nach.
Das TPC-H-Ergebnis für DB2 9 scheint noch nicht veröffentlicht zu sein. Mal sehen, wann das erscheint.
Das TPC-C-Ergebnis kenne ich schon seit einigen Monaten. Auf den ersten Blick sieht es recht beeindruckend und eindeutig aus. Wenn man allerdings berücksichtigt, dass die Benchmarks auf jeweils unterschiedlicher Hardware gefahren wurden, relativiert sich der eine oder andere deutliche Vorsprung in Sachen reiner Performance.
Man sieht aber auf jeden Fall, dass DB2 9 in Sachen TPC-C besser performt als Oracle 10g.
Gerade im Vergleich mit Oracle wäre ein IDS-Benchmark spannend.
Anlässlich der "Information on Demand"-Konferenz verkündet IBM erste Erfolge bei der Kundengewinnung mit DB2 9.
"Hundreds of customers across different industries have already embraced DB2 9 and many are moving their databases from Oracle to IBM’s new data server, including: American Electric Power, Central Michigan University, Farmers Insurance and Teleglobe." Dabei sollen vor allem die neue Features wie Kompression und XML-Unterstützung für den Sinneswandel ausschlaggebend gewesen sein.
Ich bin bei solchen Meldungen erst mal skeptisch. Erfolge im Wettbewerb werden langfristig in Zu- oder Abnahme von Marktanteilen gemessen. Warten wir also die nächsten Gartner- oder IDC-Studien ab. Auch wenn ich von diesen Studien nicht viel halte, Bewegungen am Markt werden sie hinreichend reflektieren.
Sicher, die neuen Features von DB2 9 sind aus technischer Sicht überzeugend, aber reicht das, um alte, eingeschworene Oracle-Anwender zu einer in der Regel aufwändigen Migration zu bewegen?
Ob DB2 9 auch aus geschäftlicher Sicht gegen Oracle überzeugt, wird wohl mühsam im Einzelfall in PoCs nachgewiesen werden müssen.
|
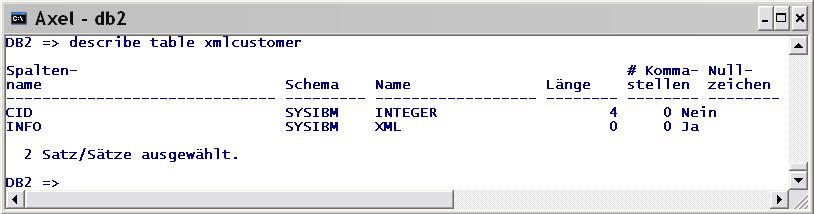 Ich nehme die Tabelle XMLCUSTOMER aus der DB2 Sample-Datenbank. Sie hat zwei Spalten, CID und INFO. CID ist vom Typ Integer, INFO vom Typ XML.
Ich nehme die Tabelle XMLCUSTOMER aus der DB2 Sample-Datenbank. Sie hat zwei Spalten, CID und INFO. CID ist vom Typ Integer, INFO vom Typ XML.

 ap127
ap127