Saturday, 28. October 2006
Bevor man Data Mining in DB2 betreiben kann, muss vorher die jeweilige Datenbank dafür vorbereitet werden. Dies geschieht mit
idmenabledb ... fenced dbcfg
im DB2 Befehlsfenster (wobei an Stelle von ... natürlich der Datenbankname stehen sollte).
Damit wird ein Schema erstellt, unter dem dann einige Tabellen und eine Vielzahl von Anwendungsobjekten (datentypen, Funktionen, Prozeduren und Methoden) angelegt werden.
Im Design Studio gibt es hierzu (noch) keinen Eintrag im Kontextmenu der Datenbank, so wie es das die Anlage der OLAP-Objekte vorgesehen ist. (23.11.2006: Tatsächlich findet man solch einen Eintrag im Datenbankexplorer)
Eine der hilfreichsten von vielen nützlichen Funktionen im Design Studio ist "In Modell speichern". Sie ist jeweils unter "Virtuelle Tabelle" in den Eigenschaften der Ein- und Ausgabeports verfügbar. So kann ganz einfach eine durch einen Operator erstellte Ausgabe sofort im Modell als Tabelle widerspiegelt werden. Diese Tabelle kann ich dann z.B. als Tabellenziel am Ende des Flusses verwenden.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Um das alles ein wenig abzukürzen: Im Falle des Scorer geht das schief.
"Schiefgagangen" vollständig lesen
Hier sind zwei der Kleinigkeiten, die mir das Entwickeln eines Minig-Flusses erleichtern:
Friday, 27. October 2006
Ein Fluss muss nicht wie der andere sein.
Zumindest ist das im Design Studio recht offensichtlich. Hat man einige Datenflüsse und Minig-Flüsse erstellt, sieht man recht schnell, dass dahinter wohl unterschiedliche Entwicklerteams stecken. Das zeigt sich an vielen Kleinigkeiten.
Und auch an einer Funktion, die bisher nur dem Mining-Fluss-Entwickler zur Verfügung steht: "Bis zu diesem Schritt ausführen ...". Genial ...
Rechte Maustaste drücken auf einem Operator in Mining-Fluss und den Punkt im Kontextmenü auswählen. Der Rest ist selbstredend. Es können also beliebige Teilflüsse getestet werden, natürlich ohne dass der Mining-Fluss vollständig sein muss.
Dieses Feature wäre auch für das Erstellen und Test von Datenflüssen hilfreich. Wieder ein Feature für zukünftige DWE-Versionen.
Ich habe leider noch keinen einfachen Weg gefunden, um einen Operator auf dem Panel des Design Studios per Copy/Paste (mit dem Kontextmenü oder mit "Bearbeiten") oder per Drag-and-Drop zu kopieren.
Bei aufwändig gefüllten Operatoren wäre das schon eine große Hilfe. Es gibt aber da noch die XML-Dateien, die Daten-, Mining- oder Steuerungsflüsse beschreiben. Mit etwas Aufwand, lässt sich die XML-Darstellung des begehrten Operators aus der Quelldatei kopieren und in die Zieldatei einfügen.
Es gibt aber einen schnelleren Weg, wenn nur Operatoren aus einem Fluss kopiert werden sollen: Kopiere als Erstes den gesamten Fluss im Projektexplorer mit dem Kontextmenu und lösche alle nicht gebrauchten Operatoren.
Trotzdem: Copy, Cut und Paste für definierte Operatoren wären ein hübsches Feature für eine der 9.1-Nachfolgeversionen.
Monday, 23. October 2006
Diese Ankündigung habe ich noch nicht bei ibm.com gefunden. Daher gibt es hier auch keinen Link, und daher konnte ich keine Details nachsehen. Einige Fragen bleiben also offen, spätestens bis ich die Version 9.1.1 installiert habe.
Das wird dann auch nicht mehr solange auf sich warten lassen: am 1.12. steht der Refresh zum Download bereit, also noch im 4.Quartal, so wie prognostiziert.
Die wesentliche Neuerung dieser Hundertstel-Version ist die Einbindung der aktuellen DB2-Version 9.1. Dies hätte möglicherweise auch mit der DWE 9.1 funktioniert, aber mit der 9.1.1 ist es nun offiziell. Und man weiß ja nie, was so passieren kann.
Damit stehen nun der DWE alle neuen Features der DB2 9 wie
- Self-Tuning Memory Management
- Table (Range) Partitioning und
- Table (Row) Compression
zur Verfügung. So zu lesen in der Ankündigung. Mal sehen, wie sich dies im SQW niederschlägt.
Saturday, 7. October 2006
Bei neuer Software sollte man schon mal ins Handbuch schauen. Das Design Studio der DWE ist neu, das "Handbuch" ist sehr umfangreich - ganz entsprechend der Funktionsvielfalt der dokumentierten Anwendung. Ich war eben wieder mal lesefaul. Also muss ich nun Abbitte leisten:
Da habe ich mich doch vor Zeiten beschwert, dass sich im Datenimport-Operator Feldtrenner und Zahlenformat nicht aus einer Liste bequem auswählen lassen.
So sind als Trenner unter Eigenschaften/Dateiformat STANDARD, TAB, ", %, das Komma und anderes selektierbar, wobei unter STANDARD das Komma verstanden wird. Eine Drop-down-Liste für Zahlenformate ist erst gar nicht vorgesehen. Also habe ich unwissend, wie ich nun mal war, die Quelldatei entsprechend aufbereitet - mit Komma als Feldtrenner und dem angelsächsischen Dezimalpunkt.
Hätte ich nur in der Doku oder im Tool-Tip nachgeschaut, was ich alles unter "Zusätzliche Dateitypmodifikatoren" eintragen kann. Das ist immerhin ein MLE mit viel Platz für alle möglichen Optionen, so z.B. für
modified by coldel; decpt,
(oder einfach: coldel; decpt, )
Und genau hätte mein Problem gelöst. Zwar nicht per Auswahl aus einer Drop-down-Liste, aber immerhin.
Dadurch wird der NLS nicht vollständig, aber ich hatte da tatsächlich was übersehen.
Thursday, 24. August 2006
Wie bekomme ich bloß meine Daten aus MS Access in mein Data Warehouse?
Fürs erste habe ich sie mühsam in eine CSV-Datei exportiert, um sie mit dem Dateiimportoperator in die dafür vorgesehen DB2-Datenbank zu importieren.
Um das ganze aber weniger händisch betreiben zu können, hatte ich vor, nach einer JDBC-ODBC-Bridge zu googlen. Aber auch das wäre viel zu kompliziert gewesen. Martin erinnerte mich daran, dass DB2-Tabellenfunktionen auch OLEDB unterstützen.
Die Umsetzung dauerte dann nur einige Minuten: In der DB2 Entwicklungszentrale mit dem Assistenten eine OLEDB-Tabellenfunktion erstellen und diese dann im DWE Design Studio mittels des Tebellenfunktionsoperators zum Ausgangspunkt eines Datenfluss machen.
Es geht sogar noch etwas einfacher.
Tuesday, 22. August 2006
Namen sind angeblich nur Schall und Rauch. Das sollte dann auch für Namen in Datenbanken gelten. Ob eine Tabelle nun "Umsatz" heißt oder "xxx" ist der Datenbank egal.
Ich mache aber immer wieder die Erfahrung, dass es zwar egal ist, welchen Namen das Datenbankkind bekommt, aber der sollte wenigstens groß geschrieben werden. Das gilt für Namen von Datenbanken selbst, sowie für Namen von Objekten in einer Datenbank.
Immer, wenn ich diesem Prinzip nicht gefolgt bin, hatte ich später irgendwo größeren Schreibaufwand. Manche Anwendungen gehen schon mal davon aus, dass Schema- oder Tabellennamen groß geschrieben sind.
Zumindest ist diese Regel besser als die blödsinnigen eckigen Klammern, die Access verwendet.
Monday, 21. August 2006
 Was steht im Titel? Es ist untersagt hier weiter zu lesen.
Also raus jetzt.
...
"Dies nicht lesen" vollständig lesen
Sunday, 20. August 2006
Noch ein Wort zum Dateiimport-Operator des SQL-Warehousing-Tools der DB2 Datawarehouse Edition:
Das Semikolon scheint als Trenner zwischen Feldern nicht vorgesehen zu sein.
Einige Formate lassen sich definieren: Datum, Zeit und Zeitstempel. Unter den wählbaren Datumsformaten fehlt mir DD.MM.YYYY. Irgendwie konsequent ist daher, dass das kontinental-europäische Dezimalkomma nicht unterstützt wird.
Zahlenformate sind nicht wählbar. Beim Exportieren aus (z.B.) MS Access muss also das voreingestellte Dezimalzeichen von "," auf "." geändert werden. Entsprechendes wird für Datumstrennzeichen gelten.
Ist der NLS noch unvollständig oder habe ich da was übersehen?
Lesen bildet, manchmal selbst das Lesen von solch Meisterwerken wie Online-Hilfen. Ich bin stets freudig überrascht, wenn dies umgehend zu praktisch verwertbaren Erkenntnissen führt wie z.B. die prompte Beantwortung meiner "Dateiimport"-Frage .
Ich hätte diese Frage auch anders klären können: Durch einen Blick ins Log.
Dazu sollte man unter Datenfluss/Ausführen auf der Seite "Diagnose" eine Tracestufe auswählen. Aber Vorsicht: Die Tracestufe "Beides" kann ein sehr großes Logfile nach sich ziehen.
Die Tracemeldungen werden nach Beendigung der Ausführung im "Auführungsergebnis" präsentiert. Ungeduldige können sie ruhig mit "OK" wegklicken. Sie sind bereits unter ...\workspaces\[Projektname]\run-profiles\logs gespeichert.
Handbücher beschreiben die Theorie, Logfiles dagegen die Praxis.
Wednesday, 16. August 2006
Ich mag Handbücher, die meine Fragen bereits antizipiert haben.
Eigentlich vermeide ich die Konsultation von solchen Dokumenten, aber manchmal geht es nicht ohne. 2,5 GB bringen entsprechend viel Dokus und Tutorials mit sich - soweit ich gesehen habe mehrere 100 MB. Die werde ich nicht alle lesen.
Hier meine Frage, die unbürokratisch von der Online-Hilfe beantwortet wurde:
Mein Datenfluss hat einen Dateiimportoperator als Quelle und verzweigt sich danach sofort in drei Operatoren-Stränge. Da der Dateiimportoperator eine große CSV-Datei einliest und konvertiert, könnte es ja sein, dass dies möglicherweise dreimal durchgeführt wird - für jeden Zweig am Ausgabe-Port des Dateiimports einmal.
Glücklicherweise gibt es den Datenstationsoperator. Dieser speichert jede Tabelle zwischen - als Datei, als View, als temporäre oder als permanente Datenbank-Tabelle. Dieser Operator wäre also in der Lage, ein mögliches mehrfaches Einlesen zu verhindern.
Aber ist das explizite Einbauen eines Datenstationsoperators wirklich notwendig. Oder ist das SQL Warehousing-Tool (SQW) der DWE schlau genug und baut so einen Operator selbstständig ein?
Tuesday, 15. August 2006
Das ist wahre Begeisterung: Nachdem ich den Plan für mein eigenes DWE-Tutorial niedergeschrieben hatte, konnte ich bis 4 Uhr morgens nicht mehr die Finger davon lassen. Die erste Etappe habe ich auch tatsächlich erfolgreich beendet. Der Rest ist dann OLAP.
Zugegeben: Es ist nicht immer alles glatt verlaufen. Aber das sind die typischen Probleme in der Kennenlernphase einer neuen Software. Immerhin habe ich keine Dokumentation zu Rate ziehen müssen und auch nicht wollen. Fast alles erklärt die Software selbst. Eigentlich überraschend.
Ok, ich habe ein, zwei mal im offiziellen DWE Tutorial nachgeschaut.
Hier in Überschriften das Protokoll dieses famosen Projektstarts: - Anlegen einer leere Datenbank mit DB2-Bordmitteln
- Anlegen eines "Data-Warehouse-Projekts" im Design Studio (ich mag das DWE Design Studio, denn das Design Studio basiert auf Eclipse)
- Importieren der Metadaten der unter 1. angelegten DatenbankAnlegen eines "Datenfluss" zum Importieren der Daten aus MS Access
- Definieren eines "Dateiimport"-ObjektesOperators
- Erstellen des Modells für die Zieltabelle
- Definieren eines "Massenladeziel"-ObjektesOperators zum Befüllen der Zieltabelle mit den importierten Daten
- Prüfen des Datenflusses
- Erstellen der neuen Tabelle (siehe 6.) in der Datenbank
- Ausführen des Datenflusses
Nachdem 10. erfolgreich war, wurde ich mutig und habe noch zwei weitere, ein wenig längere Datenflüsse gebaut.
Hier noch einige Details zu den Überschriften:
Monday, 14. August 2006
... oder zu neuschwäbisch: Business Intelligence. Das soll mit der DB2 Datawarehouse Edition erreicht werden können. Nun gut, lasst es uns testen!
Dazu nehme ich eine alte MS-Access-Anwendung her, um sie beispielhaft zu portieren und zu verbessern. Dies ist mein Tutorial zum Einstieg in die Data Warehouse Edition.
Nachdem ich hier die Installation der DWE beschrieben und kommentiert habe, werde ich dies teilweise für dieses kleine DWE-Projekt tun. Dies soll der Dokumentation und der Wiederverwendbarkeit dienen.
Und hier die Aufgabe: Einlesen der Daten aus einer Access-Tabelle, Erstellung eines OLAP-Modells für diese Daten, Erstellung des Würfels und Implementierung der wichtigsten Reports und Analysen mit Alphablox.
Anders als meine Access-Anwendung, kann ich dann alle Prozesse und Analysen auf einem Server ausführen und auf die Ergebnisse mit einem Browser zugreifen. Dies fördert die Klugheit eines Unternehmens.
|
 Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.
Auch der Scorer-Operator hat einen Ausgabeport und die dazugehörige virtuelle Tabelle. Diese Tabelle enthält zwei vom Operator kreierte Spalten: CLUSTER_ID und CLUSTER_QUALITY. Klar, dass ich diese Spalten auch in einer realen Tabelle irgendwann mal sehen will. Also nichts einfacher als das mit "In Modell speichern". Eine Übung, die bisher immer funktioniert hat.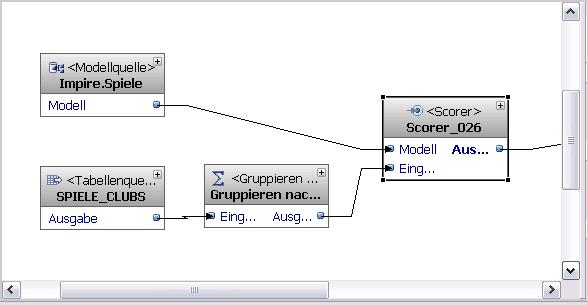
 Zugegeben: Es ist nicht immer alles glatt verlaufen. Aber das sind die typischen Probleme in der Kennenlernphase einer neuen Software. Immerhin habe ich keine Dokumentation zu Rate ziehen müssen und auch nicht wollen. Fast alles erklärt die Software selbst. Eigentlich überraschend.
Zugegeben: Es ist nicht immer alles glatt verlaufen. Aber das sind die typischen Probleme in der Kennenlernphase einer neuen Software. Immerhin habe ich keine Dokumentation zu Rate ziehen müssen und auch nicht wollen. Fast alles erklärt die Software selbst. Eigentlich überraschend.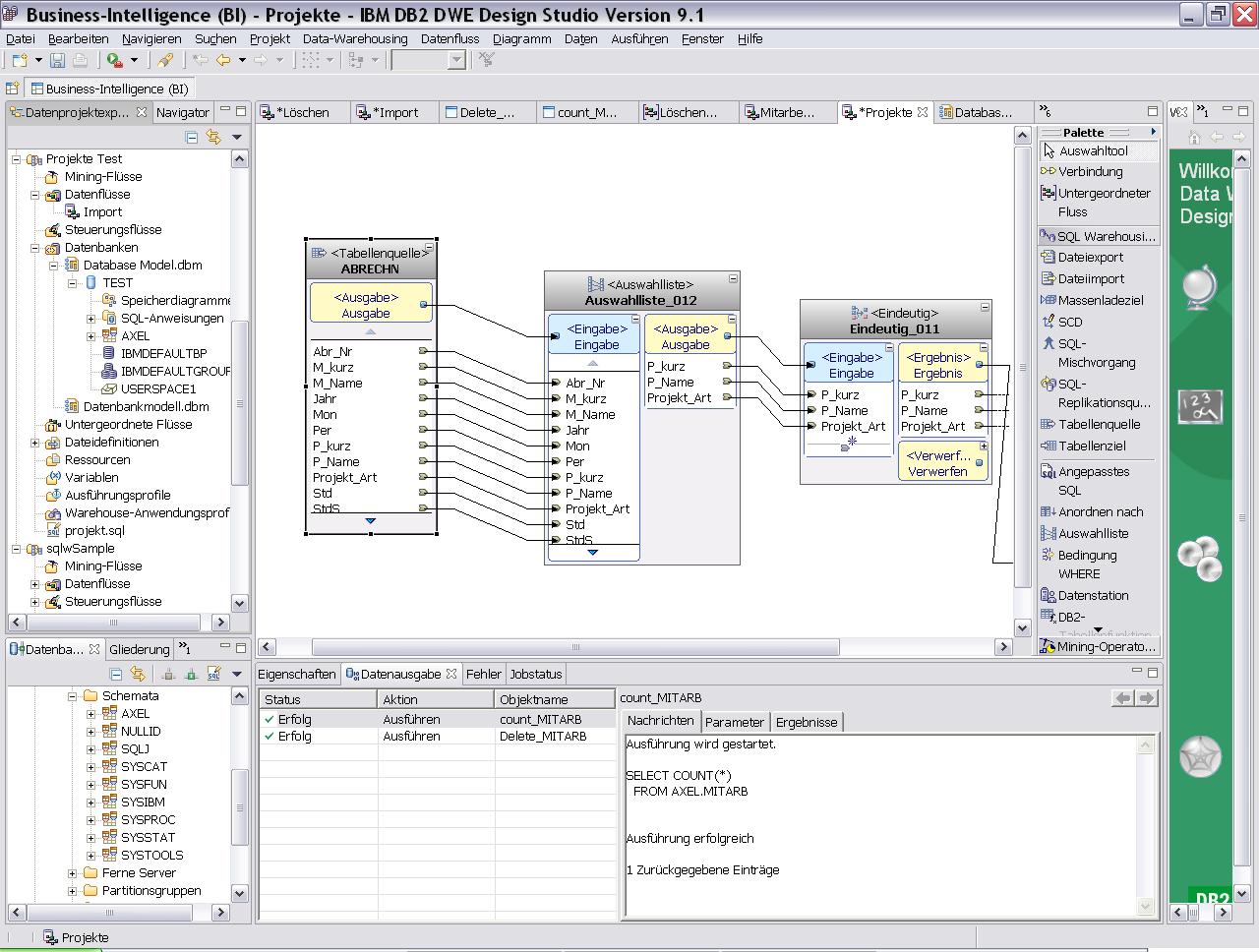

 ap127
ap127